Fig. 1. Heuristic Rule 1
Stan Szpakowicz, Stan Matwin, Ken Barker
Department of Computer
Science
University of Ottawa
Ottawa, Ontario, Canada K1N 6N5
{szpak,
stan, kbarker}@csi.uottawa.ca
WordNet [Miller, 1990; Beckwith et al., 1991] is a very rich source of lexical knowledge. Since most entries have multiple senses, we face a problem of ambiguity. The motivation for the work described here has been the desire to design a WSD algorithm that satisfies the needs of our project without large amounts of hand-crafted semantic facts or statistical elaboration of very large corpora. We propose an algorithm that works well on small unprepared texts. Published reports on WSD usually quote a number that expresses the composite performance of the algorithm on some test cases. Our number is 73%. It is not nearly as high as the 96% reported in [Yarowski, 1995] or even as the 77% in [Luk, 1995]. Those two experiments, however, dealt with "large" (460M words) and "relatively small" (1M words) corpora, respectively. In comparison, our test text might be called "minuscule": it has less than 30,000 words and an average of 61 occurrences of each noun.
We concentrate on using information in WordNet and minimizing the need for other knowledge sources. Semantic similarity between words (defined in the next section) plays an important role in the algorithm. We propose several heuristic rules to guide WSD. Tested on an unrestricted, real text (a section of the Canadian Income Tax Guide), this automatic WSD method gives encouraging results.
WSD is essential in natural language processing. Early symbolic methods, typified by [Hirst, 1987] relied on large amounts of hand-crafted knowledge. As a result, they could only work in a specific domain. To overcome this weakness, later work concentrated on statistical methods [Brown et al., 1991; Gale et al., 1992; Resnik, 1992; Schutze, 1992; Dagan et al., 1994; Lehman, 1994]. Although these methods did not require domain-specific knowledge, they required larger corpora to achieve good results. Yarowski [1995] reports a 96% average success rate, but this result was obtained on a corpus of 460 million words. Recent work on improving statistical approaches includes [Resnik, 1993; Sussna, 1993; Voorhees, 1993].
When WSD in smaller texts is required, many researchers combine some form of frequency analysis with large, readily available repositories of semantic knowledge. Kozima and Furugori [1993] compute a similarity measure between words, using spreading activation on a semantic network constructed from the printer's tape version of the Longman's Dictionary of Contemporary English (LDOCE). Their measure could be used in a disambiguation algorithm. Dolan [1994] describes a heuristic-based algorithm that decides which senses of an LDOCE headword are semantically similar, and which senses are more unrelated. Luk [1995] generalizes words according to (a slightly modified version of) the LDOCE controlled vocabulary and their definitions. By generalizing words to a fixed, relatively small number of concepts, a smaller corpus can provide enough co-occurrence data for statistical sense disambiguation.
Fukumoto and Tsujii [1995] propose disambiguation of polysemous verbs based on an elaborate clustering method that treats nouns as a context for verbs.
Resnik [1995a] uses WordNet to compute a measure of semantic similarity between two words based on the informativeness of their least upper bound (subsumer) in WordNet's IS-A hierarchy; more abstract concepts are considered less informative. The similarity of pairs of co-occurring words is computed, and descendants of the most informative subsumer are preferred candidates for the disambiguated sense.
It has become common to use some measure of semantic similarity between words to support WSD [Resnik, 1992; Schutze, 1992; Resnik, 1995b]. In this work, we have adopted the following definition: semantic similarity between words is inversely proportional to the semantic distance between words in WordNet's IS-A hierarchy. By investigating the semantic relationships between two given words in WordNet hierarchies, semantic similarity can be measured and roughly divided into three levels.
Level 1: The words are strict synonyms according to WordNet: both belong to the same synset.
Level 2: The words are hyponyms or hypernyms: one word is the parent of the other word in the IS-A hierarchy.
Level 3: The words are siblings[1]: they are not in the same synset, but they have a common parent node in the IS-A hierarchy.
Although we have only applied the WSD algorithm to noun objects in a text (that is, nouns that are objects of verbs in sentences successfully analyzed by the linguistic module of our system), it can also be applied to other noun phrases in a sentence, in particular subjects.
In this approach, we must consider contexts that are relevant to our method and the semantic similarity in these contexts.
For all practical purposes, the possible senses of a word can be found in WordNet, but--due to its extremely broad coverage--most words have multiple senses. To choose a single sense for a given word occurrence, the word's context can be used. The notion of context and its use could differ widely across WSD methods. One may consider a whole text, a 100-word window, a sentence or some specific words nearby, and so on. In our work, we consider as context the verbs that dominate noun objects in sentences. That is, we investigate verb-noun pairs to determine the intended meaning of noun objects in sentences.
In this work, then, we focus on investigating two aspects of semantic similarity:
* The semantic similarity of the noun objects.
* The semantic similarity of their verb contexts.
The basic premise of the algorithm is that the correct sense of a noun can be determined by looking at its dominating verb. If an unambiguous--or disambiguated--occurrence of the same noun (or a semantically similar noun) can be found elsewhere in the text with the same verb (or a semantically similar verb), we can use that noun sense to disambiguate the current noun. This approach is based on the observation that polysemous nouns tend toward single or few senses within a given text. In an experiment cited by Yarowski [1995], in 99.8% of cases where a word occurred more than once in a discourse, it took on the majority sense for that discourse. Our approach implicitly exploits this property by assigning high confidence to senses already known to occur in the text in semantically similar contexts.
Suppose that the algorithm seeks the intended meaning of a noun object N[2] in its verb context V, that is, the intended meaning of N in a verb-object pair (V, N). N has n candidate word senses in WordNet. In the Figures, Sk is the kth word sense of N in WordNet, 1 <= k <= n, and Sim denotes semantic similarity.
Five heuristic rules have been adopted for the WSD algorithm. Two of them rely on previously acquired results of disambiguation.
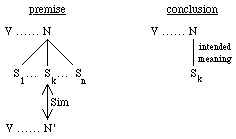
Heuristic Rule 1 (HR1): Find another noun N' in the same context V such that N' is semantically similar to Sk, one of the senses of N. Accept Sk as the sense of N in this context (see Fig. 1 and the example in STEP 2 and STEP 3 of the WSD algorithm in the next section).
Fig. 1. Heuristic Rule 1
Heuristic Rule 2 (HR2): Find a verb-object pair (V', N) in which V' is semantically similar to V[3]. If N has already been disambiguated in context V', select the same sense for N in context V (see Fig. 2 and the example in STEP 4 of the WSD algorithm).
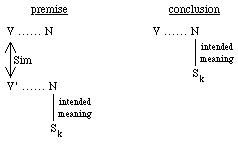
Fig. 2. Heuristic Rule 2
Heuristic Rule 3 (HR3): Find a verb-object pair (V', N') in which V' is semantically similar to V and N' is similar to Sk, one of the senses of N. Accept Sk as the sense of N in this context (see Fig. 3 and the example in STEP 5 and STEP 6 of the WSD algorithm).
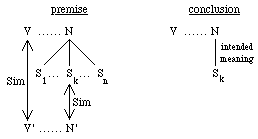
Fig. 3. Heuristic Rule 3
HR1 is the main heuristic rule in the algorithm. HR2 is not always feasible. It contributes to the inference of further results based on the previously established results. HR3 infers results from an even weaker semantic similarity between noun-verb pairs.
In addition to the three heuristic rules based on semantic similarity between noun-verb pairs, we have also formulated ad hoc heuristic rules based on specific syntactic indicators (see [Grefenstette and Hearst, 1992] for a similar approach).
Heuristic Rule 4 (HR4): Find in the text the expression "such as" following the pair (V, N)[4]. The noun N' following "such as" can be, with high confidence, considered semantically similar to a sense of N. Select this sense as a result (see Fig. 4 and the example in STEP 7 of the WSD algorithm in the next section).
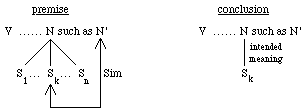
Fig. 4. Heuristic Rule 4
Heuristic Rule 5 (HR5): Find a coordinate verb group with a common object N. We currently consider two types of such groups: "V and V' ", "V or V' ". If N has already been disambiguated in the verb context V', select the same sense in context V (see Fig. 5 and the example in STEP 8 of the WSD algorithm).
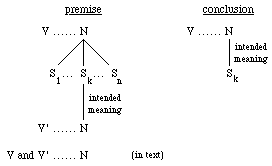
Fig. 5. Heuristic Rule 5
HR4 only aims at one kind of special cases and its coverage is limited. HR5, like HR2, also depends on previously acquired results, but its coverage is also limited.
Because the results acquired by applying different heuristic rules have different accuracy, we have defined post hoc confidence factors (henceforth CF)--a measure of plausibility of the result for various heuristic rules and levels of semantic similarity. CF values, ranging between 0 and 1, intuitively reflect the notion of decreasing semantic similarity. The assignment of CF values is arbitrary, but it reflects the relationship between the intuitive confidence in the correctness of the disambiguation and the kind of heuristic and WordNet relationships used in the disambiguation process.
CF = 1.0: This value is assigned if N has only one word sense in WordNet.
CF = 0.9: The results have been acquired by applying HR1 when there is a level 1 or level 2 similarity between N and N'.
CF = 0.8: The results have been acquired by applying HR1 when there is a level 3 similarity between N and N'.
CF = 0.7: The results have been acquired by applying HR2 when the meaning of N in the context V' has been determined by WSD with CF of 0.9 or 0.8.
CF = 0.6: The results have been acquired by applying HR3 in the presence of a level 1 or level 2 similarity between N and N'.
CF = 0.5: The results have been acquired by applying HR3 in the presence of a level 3 similarity between N and N'.
CF = 0.9 is also assigned to the results produced by applying the ad hoc rule HR4.
If rule HR5 has been applied to "V and V' ...... N", the CF value assigned to the sense of N in the context V is the same as the value previously assigned to the sense of N in the context V'.
Suppose a noun N has n word senses in WordNet. We look for sense(N, k), 1 <= k <= n, which is the intended meaning of the noun object N in a verb context V. The algorithm attempts to disambiguate a given noun in eight ways by going through eight steps. If any step succeeds, the remaining ones are skipped. We try to apply heuristic rules 4 and 5 only after rules 1-3 have failed, since these two are more ad hoc than the first three. We believe, however, that senses found using HR4 are good candidates (CF = 0.9), and therefore we might apply HR4 before steps 3-6[5]. Furthermore, since HR5 may give a CF as high as 0.9, it could also be applied before STEP 3; on the other hand, even if it succeeds, CF maybe as low as 0.5. In an enhanced version of our algorithm, successful application of HR5 would not short-circuit the remaining steps: the rule would be tried early, but its outcome accepted only after all steps with higher CFs have failed.
STEP 1: Search for N in WordNet. If N only has one sense, sense(N, 1), the meaning of N in the verb context V is sense(N, 1). The confidence in this result is 1.0.
For example, let N = income. It has one sense in WordNet, denoted sense(income, 1): "financial gain". The meaning of income in any context is sense(income, 1).
STEP 2: Find a verb-object pair (V, N') in the parsed text such that N' is synonymous or hyponymous with sense(N, k). The meaning of N in the verb context V is sense(N, k). This step corresponds to HR1 with levels 1-2 semantic similarity. The confidence in this result is 0.9.
For example, let N = contribution and V = make. contribution has 5 senses in WordNet. The verb-object pair make donation can be found in the text and donation is synonymous with sense(contribution, 3): "an amount of money contributed". Thus, the meaning of contribution in the verb context make is sense(contribution, 3).
STEP 3: The same as STEP 2, but with a sibling relationship instead of synonymy or hyponymy between N' and sense(N, k). This step corresponds to HR1 with level 3 semantic similarity. The confidence in the result is 0.8.
For example, suppose that N = credit and V = transfer. credit has 8 senses in WordNet. The verb-object pair transfer amount occurs in the text and amount is a sibling of sense(credit, 1): "money available for a client to borrow". The meaning of credit in the context transfer is sense(credit, 1).
STEP 4: Find in the parsed text a verb-object pair (V', N) in which V' is in a synonymy, hyponymy or sibling relationship with V, and N has already been disambiguated in context V'. Suppose the sense selected is sense(N, k). The meaning of N in the verb context V is also sense(N, k). This step corresponds to HR2. The confidence in this result is 0.7.
For example, take N = contribution and V = change. contribution has 5 senses in WordNet. The verb-object pair make contribution appears in the text and change is a hypernym of make. The meaning of contribution in the context make has already been established--it is sense(contribution, 3) from the example in STEP 2. Therefore, the meaning of contribution in the verb context change is also sense(contribution, 3).
STEP 5: Find in the parsed text a verb-object pair (V', N') in which V' is in a synonymy, hyponymy or sibling relationship with V and N' is synonymous or hyponymous with sense(N, k). The meaning of N in the verb context V is sense(N, k). This step corresponds to HR3 with levels 1-2 semantic similarity between nouns. The confidence in this result is 0.6.
For example, suppose N = deduction and V = calculate. deduction has 6 senses in WordNet. The text contains the verb-object pair subtract allowance. subtract is a hyponym of calculate and allowance is a hypernym of sense(deduction, 2): "an amount or percentage deducted". So, the meaning of deduction in the verb context calculate is sense(deduction, 2).
STEP 6: The same as STEP 5, but with a sibling relationship instead of synonymy or hyponymy between N' and sense(N, k). This step corresponds to HR3 with level 3 semantic similarity between nouns. The confidence in the result is 0.5.
For example, N = investment and V = list. investment has 3 senses in WordNet. The verb-object pair enter credit can be found in the text. enter is a sibling of list and credit is a sibling of sense(investment, 1): "any valuable or useful possession". The meaning of investment in the context list is, therefore, sense(investment 1).
STEP 7: Find in the parsed text the structure "such as N'" following the verb-object pair (V, N). Let N' be synonymous or hyponymous with sense(N, k). The meaning of N in the verb context V is sense(N, k). This step corresponds to HR4. The confidence in this result is 0.9.
For example, suppose N = property and V = sell. property has 5 senses in WordNet. The structure "such as real estate" appears in the text after "sell property" (that is, we have "... sell property, such as real estate ..." ) and the object real_estate is hyponymous with sense(property, 1): "any tangible possession that is owned by someone". The meaning of property in the verb context sell is sense(property, 1).
STEP 8: Find in the parsed text a coordinate verb phrase structure "V and V'" or "V or V'" whose noun object is N. Assume that sense(N, k) of N in context V' has already been picked. The meaning of N in the verb context V is also sense(N, k). This step corresponds to HR5. The confidence in this result is the same as for the verb context V'.
For example, suppose that N = property and V = dispose_of. property has 5 senses in WordNet. In the text, we find the structure "... dispose of or sell property ...". The meaning of its object property in the verb context sell has already been established. It is sense(property, 1) with CF = 0.9--see the example in STEP 7. The meaning of property in the verb context dispose_of is also sense(property, 1). The confidence in this result is also 0.9.
We have carried out a post hoc evaluation of the results, based on a manual rating of the noun-verb pairs produced by WordNet. The procedure is described later in this section. Clearly, manual rating is subjective, because it reflects the linguistic knowledge of the rater. Such assessment is, however, accepted in the literature and has been used to evaluate other disambiguation methods. In order to diminish subjectivity, four people rated the sample independently.
The WSD algorithms may produce the following types of results:
One correct answer--one reasonable meaning of the noun object (preferred by the human raters) has been selected by the WSD algorithm.
For example, for the pair report loss, only one among 8 candidate word senses, sense(loss, 5), has been selected by the WSD algorithm as the intended meaning of loss in the verb context report.
Sense 5: loss--(the amount by which the cost of a business exceeds its revenue; "the company operated at a loss last year") -> sum, sum of money, amount, amount of money
Correct multiple answers--more than one reasonable meaning of the noun object has been selected by the algorithm. Because some verbs cannot impose strong enough restrictions on their objects, it is possible for several senses of a noun to be acceptable in a verb context.
For example, for the verb-object claim charge, among 14 candidate word senses, two senses of charge have been selected by the algorithm as the intended meaning of charge in the verb context claim: sense(charge, 3) and sense(charge, 8). In fact, both are reasonable in this context.
Sense 3: charge--(the price charged for some article or service) -> cost
Sense 8: charge--(a financial liability; such as a tax) -> liability, financial obligation, indebtedness, pecuniary obligation
Partially correct answer--more than one sense of the noun has been selected by the algorithm. Among those there is a sense that is reasonable in the verb context.
For example, for the verb-object deduct benefit, among 3 candidate word senses, two senses of benefit have been selected as the intended meaning of benefit in the verb context deduct: sense(benefit, 1) and sense(benefit, 2). Of these two senses, only sense(benefit, 2) is reasonable in this context.
Sense 1: benefit, welfare--(something that aids or promotes well-being: "for the common good") -> good, goodness
Sense 2: benefit--(financial assistance in time of need) -> payment--(a sum of money paid)
Wrong answer--no noun sense selected by the algorithm is reasonable in this verb context.
No answer--no result has been produced by the algorithm. This happens if there is insufficient information in the text to support the WSD process.
In order to evaluate how disambiguation proposed by the algorithm resembles disambiguation performed by raters, we proceed as follows.
For every (V, N) pair separately, the rater inspects the WordNet senses of N. He select no more than three senses that he deems appropriate with V, and ranks the selected ones. It is possible to dismiss all the senses.
The ratings are then matched against disambiguation proposed by the WSD algorithm. We use a seven point scale:
(a) The rater's top choice is identical with WSD's single choice.
(b) The rater's top choice is among WSD's equally weighted multiple choices.
(c) The rater's second choice is WSD's single choice.
(d) The rater's second choice is among WSD's multiple choices.
(e) The rater's third choice is WSD's single choice.
(f) The rater's third choice is among WSD's multiple choices.
(g) None of the above.
WSD results, ordered from the best possible outcome (a) to the worst possible outcome (g) and matched against the preferences of four raters, are shown in Table 1.
outcome rater 1 rater 2 rater 3 rater 4
======= ====== ======= ======= =======
a 136 133 136 129
b 44 50 49 34
c 66 66 97 91
d 13 6 10 26
e 30 20 38 28
f 4 2 7 5
g 123 139 79 103
------- ------ ------- ------- -------
% of non-g 70.4 66.6 81.0 75.2
The noun senses chosen by a rater for each verb-noun pair were ordered by preference, but they were all deemed appropriate. If three appropriate choices could not be made, the rater would pick two or even fewer. Multiple acceptable choices are often possible because many WordNet senses differ only slightly. For example, the word money means "a medium of exchange that functions as legal tender" and "the official currency issued by a government". Resnik [1995a] also notes the subtlety of WordNet senses: "disambiguating word senses to the level of fine-grainedness found in WordNet is quite a bit more difficult than disambiguation to the level of homographs." Consequently, although outcomes (b) through (f) do not mark as definite a success as outcome (a), they do not indicate failure. Resnik raises another valid point: avoiding inappropriate senses is as important in some applications as disambiguating to a single sense. An example of such an application is keyword extraction for use in text summarization or information retrieval. It is likely that a query about money="legal tender" would produce useful results if hits for money="official currency" were also found.
The first conclusion from the evaluation is quite consistent among the raters: the ideal result (a) occurs in 31% to 32.7% of the cases. The second conclusion is that outcome (b) is also reasonably consistent, and it accounts for 8.2%-12% of the cases. There were considerable discrepancies between the raters in the other outcomes, particularly (c) and (g). We believe that they can be attributed to a rater's attitude during the assessment: raters 3 and 4 have taken into account the domain of the text (taxation), while raters 1 and 2 rated the verb-noun pairs on their general merits regardless of the domain. Incidentally, our algorithm has a kind of portable domain bias: an ambiguity is resolved differently in the presence of different sets of verb contexts.
We expect that the results will improve when more verb-noun pairs are available. This expectation seems to be confirmed in the literature. Experiments on texts several orders of magnitude larger than ours reported better results. An example is [Luk, 1995], although the improvement (only 4% better) is not commensurate with the 30-fold growth of the size of the text. On the other hand, many verb contexts are not discerning enough. This includes common verbs of general meaning, such as get or have, that seldom limit their noun object to a single meaning. There are--depending on the rater's attitude--between 19% and 33% no-answer cases in the test, when either WSD fails to produce an answer, or its answer is not acceptable to the rater. That is, 593 verb-object pairs in the text do not support WSD sufficiently. This difficulty could be overcome by accumulating verb-object pairs from a number of texts on the same domain, and treating them as background knowledge.
We propose a knowledge-scant approach that requires no precoded domain knowledge or general knowledge. In contrast with statistical approaches, it also does not require large corpora. Despite their size, it is not guaranteed that such corpora will contain all the senses necessary to disambiguate a particular text. Instead of precoded knowledge or large corpora, we rely on syntactic structure and a public domain lexical resource, WordNet, for the information necessary to disambiguate words. The approach, which we have described here for nouns, is based on semantic similarity of nouns in their verb contexts.
Semantic similarity is defined using WordNet relations of synonymy, hyponymy and hypernymy. We have defined simple heuristics for determining the sense of a noun from the sense of the same (or possibly similar) noun in the same (or possibly similar) context. We have implemented a WSD algorithm. We have experimented with it by comparing the results on a 30,000 word real-life text with the results of noun disambiguation performed on the same text by four human raters. We have proposed a simple evaluation methodology, based on several levels of compatibility of the raters' choices with the WSD choices. We have conducted such an evaluation and found it encouraging. The ideal outcome of a single sense found by the WSD algorithm and the rater happens for one out of three nouns; no correct meaning was found only in one of three to one of five cases (depending on presence or absence of the rater's domain-bias). This will be satisfactory for the applications that do not require that a single, correct meaning be identified all the time.
Furthermore, our results seem to indicate that the accuracy of the algorithm could benefit from even a simple identification of the topic of the text. The details of how this can be done, again using public domain lexical resources, will be part of future work.
Other future work on WSD will include experiments with slightly longer texts; evaluation of the effects of accumulating domain-specific verb-noun pairs as background knowledge; a reworking of the algorithm to apply ad hoc heuristic rules in the earlier steps; an investigation of the possibility of more complex contexts in the WSD process; an extension toward noun occurrences in positions other that the object.
[Brown et al., 1991] Brown, P. F., S. A. Della Pietra, V. J. Della Pietra and R. L. Mercer, "Word-Sense Disambiguation Using Statistical Methods", Proc 29th ACL Meeting, Berkeley 1991, 264-270.
[Dagan et al., 1994] Dagan, I., F Pereira and L. Lee, "Similarity-Based Estimation of Word Cooccurrence Probabilities", Proc 32nd ACL Meeting, Las Cruces 1994, 272-278.
[Delisle, 1994] Delisle, S., "Text Processing without A-Priori Domain Knowledge: Semi-Automatic Linguistic Analysis for Incremental Knowledge Acquisition," PhD Thesis, TR-94-02, Department of Computer Science, University of Ottawa, 1994.
[Dolan, 1994] Dolan, W. B., "Word Sense Ambiguation: Clustering Related Senses", Proc COLING-94, Kyoto 1994, 712-716.
[Fukumoto and Tsujii, 1995] Fukumoto, F. and J. Tsujii, "Word-Sense Disambiguation using the Extracted Polysemous Information from Corpora", Proc PACLING-95, Brisbane 1995, 77-84.
[Gale et al., 1992] Gale, W. A., K. W. Church and D. Yarowsky, "A Method for Disambiguating Word Senses in a Large Corpus", Computers and the Humanities, 26, 1992, 415-439.
[Grefenstette and Hearst, 1992] Grefenstette, G. and M. Hearst, "A Method for Refining Automatically Discovered Lexical Relations: Combining Weak Techniques for Stronger Results", AAAI Workshop on Statistically-Based NLP Techniques, San Jose, July 1992.
[Hirst, 1987] Hirst, G., Semantic Interpretation and the Resolution of Ambiguity. Cambridge University Press, Cambridge, 1987.
[Kozima and Furugori, 1993] Kozima, H. and T. Furugori, "Similarity between Words Computed by Spreading Activation on an English Dictionary", Proc EACL-93, Utrecht 1993, 232-239.
[Lehman, 1994] Lehman, J. F., "Toward the Essential Nature of Statistical Knowledge in Sense Disambiguation", Proc AAAI-94, 1994, 734-741.
[Luk, 1995] Luk, A. K., "Statistical Sense Disambiguation with Relatively Small Corpora Using Dictionary Definitions", Proc 33rd ACL Meeting, Cambridge 1995, 181-188.
[Miller, 1990] Miller, G., "WordNet: An On-line Lexical Database", International Journal of Lexicography, 3(4), 1990.
[Resnik, 1992] Resnik, P., "WordNet and Distributional Analysis: A Class-based Approach to Lexical Discovery", AAAI Workshop on Statistically-Based NLP Techniques, San Jose, July 1992.
[Resnik, 1993] Resnik, P., "Semantic Classes and Syntactic Ambiguity", Proc ARPA Workshop on Human Language Technology. Princeton, 1993.
[Resnik, 1995a] Resnik, P., "Disambiguating Noun Groupings with Respect to WordNet Senses", Proc Third Workshop on Very Large Corpora, Cambridge 1995.
[Resnik, 1995b] Resnik, P., "Using Information Content to Evaluate Semantic Similarity in a Taxonomy", Proc IJCAI-95, 448-453.
[Schutze, 1992] Schutze, H., "Word Sense Disambiguation With Sublexical Representations", AAAI Workshop on Statistically-Based NLP Techniques, San Jose, July 1992, 109-113.
[Sussna, 1993] Sussna, M., "Word Sense Disambiguation for Free-text Indexing Using a Massive Semantic Network", CIKM'93, 1993.
[Voorhees, 1993] Voorhees, E. M., "Using WordNet to Disambiguate Word Sense for Text Retrieval", Proc ACM SIGIR'93, Pittsburgh, 1993, 171-180.
[Yarowski, 1995] Yarowski, D., "Unsupervised Word Sense Disambiguation Rivaling Supervised Methods", Proc 33rd ACL Meeting, Cambridge 1995, 189-196.