| Previous | Table of Contents | Next |
In a fault-tolerant system, fault management encompasses the following activities:
• Fault detection - detecting the presence of a fault in the system and generating a fault report.
• Fault notification - propagating fault reports to entities that have registered for such notifications.
• Fault analysis/diagnosis - analyzing a (potentially large) number of related fault reports and generating condensed or summary reports.
In the Fault Tolerance Infrastructure, Fault Detectors detect faults in the objects, and report faults to the Fault Notifier.
The Fault Notifier receives fault reports from the Fault Detectors, filters the reports, and propagates the filtered reports
as fault event notifications to consumers that have subscribed for them. The Fault Analyzer reasons about the fault reports
that it has received, and produces aggregate or summary fault reports that it propagates back to the Fault Notifier for dissemination
to other consumers.
A fault-tolerant system typically has several Fault Detectors, including those provided by the infrastructure to monitor objects,
and other fault detectors provided by the infrastructure or the application. Each Fault Detector belongs to a particular fault
tolerance domain, and is not shared across fault tolerance domains. Most implementations of Fault Detectors are based on timeouts,
and use either pull- or push-based monitoring. This section defines an interface for pull-based monitoring, the PullMonitorable
interface, that application objects inherit, and that is invoked by a Fault Detector within the Fault Tolerance Infrastructure.
The section also defines a FaultNotifier interface. The Fault Notifier receives fault reports from the Fault Detectors. The
Fault Notifier filters the reports to eliminate unnecessary or duplicate reports. It then sends fault event notifications
to the consumers. The Replication Manager is such a consumer, as is the Fault Analyzer. The application can also subscribe
to receive fault event notifications. Logically, there is one Fault Notifier per fault tolerance domain, although typically
it is replicated for fault tolerance. The Fault Notifier belongs to a particular fault tolerance domain and is not shared
across domains.
A fault-tolerant system may also have one or more Fault Analyzers. Each Fault Analyzer collects fault reports and performs
event correlation, analysis, and diagnosis. It may condense a large number of related fault reports into a single fault report
(e.g.,
the crash of a host can cause fault reports for all objects on that host, as well as a fault report for the host itself).
The analysis of fault reports is application-dependent; thus, this chapter does not define a Fault Analyzer interface, but
allows an application developer to hook in Fault Analyzers as consumers of fault reports generated by the Fault Notifier.
A problem with fault notification is the potential for a large number of notifications to be generated by a single fault.
This problem is addressed by filtering within the Fault Notifier, by Fault Analyzers, and by the FaultMonitoringGranularity.
23.4.2 Architecture
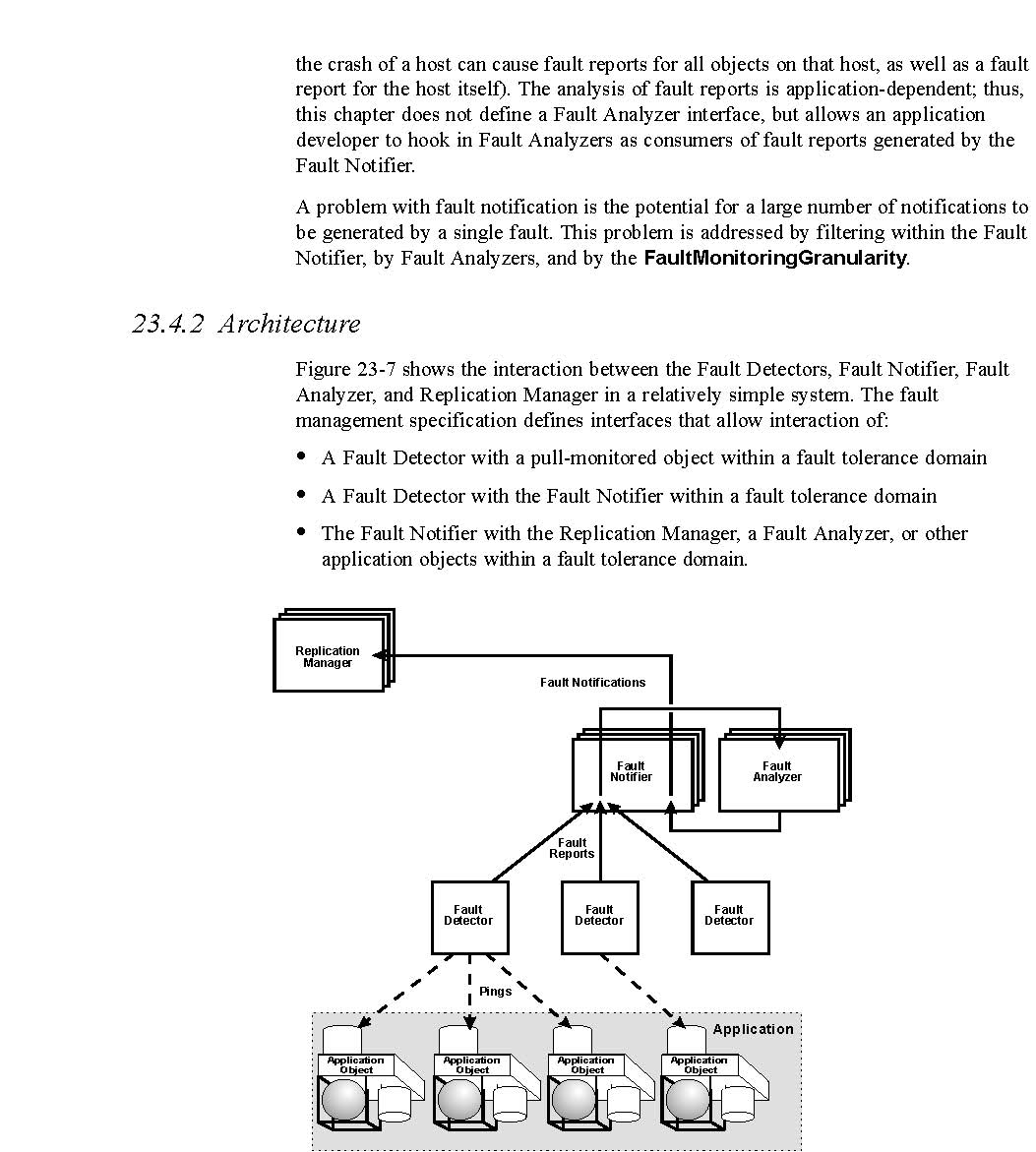
Figure 23-7 shows the interaction between the Fault Detectors, Fault Notifier, Fault Analyzer, and Replication Manager in
a relatively simple system. The fault management specification defines interfaces that allow interaction of:
• A Fault Detector with a pull-monitored object within a fault tolerance domain
• A Fault Detector with the Fault Notifier within a fault tolerance domain
• The Fault Notifier with the Replication Manager, a Fault Analyzer, or other application objects within a fault tolerance domain.
ReplicationManager
Fault Notifications
Fault FaultNotifier Analyzer
Fault Reports
Fault FaultDetector Detector
Pings
FaultDetector
Application
ApplicationObject
ApplicationObject
ApplicationObject
ApplicationObject
Figure 23-7 Interactions between the Fault Detectors, Fault Notifier, Fault Analyzer, and Replication Manager.
23.4.2.1 Fault Detection
In the Fault Tolerance Infrastructure, fault detection is initiated by the Replication Manager for members of object groups
having either application-controlled or infrastructure-controlled MembershipStyles
(see Section 23.3.2, “Fault Tolerance
Properties,? on page 23-32). Because the fault management specification focuses on
monitoring and timeout-based fault detection, the terms monitor and detector are used interchangeably.
There are two common styles of fault monitoring: PULL and PUSH. These two fault monitoring styles differ in the direction
in which fault information flows in the system. Because push-based monitoring depends on characteristics of the application,
it is not defined in this specification.
The fault management specification defines the interaction between a pull-based Fault Detector and application objects. It
defines a PullMonitorable interface that the application objects inherit. Other kinds of system-specific (for example, host,
network) and application-specific Fault Detectors may be present in the system, but they are not defined.
23.4.2.2 Fault Notification
This section defines a FaultNotifier interface that contains operations that allow a Fault Detector or Fault Analyzer to push
fault reports to the Fault Notifier. It also defines operations that allow the Replication Manager, a Fault Analyzer or other
application object to register as consumers of fault event notifications. The Fault Notifier filters fault reports that it
has received from the Fault Detectors, and propagates fault reports to the entities that have registered for such notifications.
23.4.2.3 Fault Analysis
The Fault Analyzer registers with the Fault Notifier as a consumer of fault reports. The Fault Analyzer correlates fault reports
and generates condensed fault reports. Because these activities are specific to the application or the environment, the application
developer is responsible for the analysis/diagnosis algorithm employed by the Fault Analyzer. The Fault Analyzer may use the
Fault Notifier to disseminate its condensed fault reports.
23.4.2.4 Scalability
The fault management specification does not limit the number or arrangement of Fault Detectors in a fault tolerance domain.
In a large system spanning many hosts with each host supporting many objects, arranging the Fault Detectors in a hierarchical
structure would be more scalable and efficient.
For example, consider a system where all objects at a given location (say, a process)
are monitored by a local object-level Fault Detector, as shown in Figure 23-8 on
page 23-69. The set of object-level Fault Detectors might be monitored by a process-
level Fault Detector. The set of process-level Fault Detectors might be monitored by a host-level Fault Detector. The Replication
Manager, or a consumer object created by the Replication Manager, might be implemented to consume either object-level, process-level,
or host-level fault reports. If it is implemented to consume only object-level fault reports, a Fault Analyzer that translates
object-level fault reports into process- or host-level fault reports can be attached to the Fault Notifier.
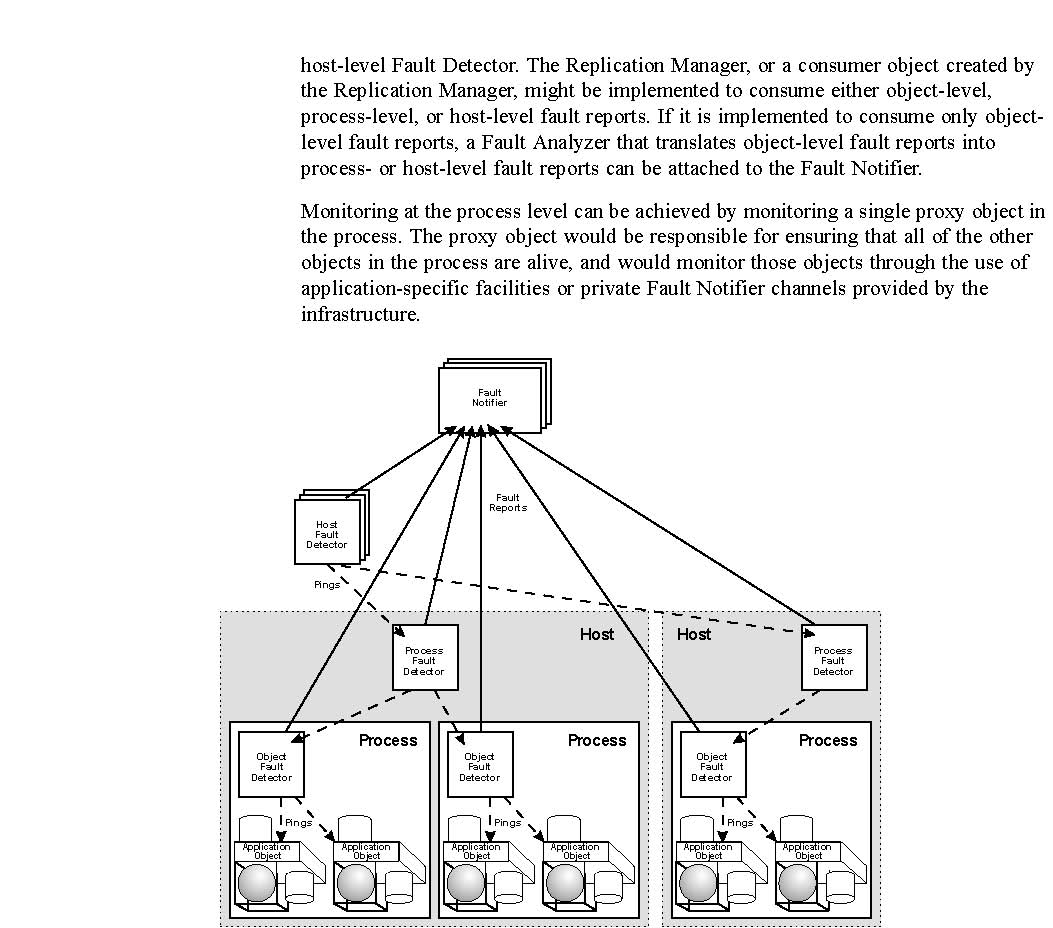
Monitoring at the process level can be achieved by monitoring a single proxy object in the process. The proxy object would
be responsible for ensuring that all of the other objects in the process are alive, and would monitor those objects through
the use of application-specific facilities or private Fault Notifier channels provided by the
infrastructure. |
|||||
| Fault Notifier | |||||
| Host Fault Detector Fault Reports | |||||
| Pings | |||||
| Process Fault Detector Host | Host | Process Fault Detector | |||
| Object Fault Detector | Object Fault Detector Process Process | Object Fault Detector | Process | ||
| Application Object Pi | ngs | Application Object Application Object Application Object Pings | Application Object Pings | Application Object | |
| Figure 23-8 | Hierarchical Fault Detection. |
This example shows the generality of the Fault Tolerance Infrastructure in handling different types of arrangements of Fault
Detectors. Other organizations are possible and useful.
23.4.2.5 Deployment of Fault Detectors
Fault Detectors can be as varied as the applications they monitor and, for these diverse applications, Fault Detectors can
be deployed in several different ways:
• Infrastructure Created Fault Detectors. The Fault Tolerance Infrastructure may create instances of Fault Detectors to meet the needs of the applications. For example, to implement the MEMB FaultMonitoringGranularity, the Fault Tolerance Infrastructure must create Fault Detectors sufficient to ping every member of the object group. Because these Fault Detectors are created (or, at least, configured) by the Fault Tolerance Infrastructure, their identities need only be known to the infrastructure.
• Application Created Fault Detectors. It might be necessary or advantageous for applications to create their own Fault Detectors. For example, applications might have unique knowledge of their operating environment, such as access to hardware indicators of faults within the operating environment. However, unlike the other types of Fault Detectors, application-created Fault Detectors are not inherently known to the Fault Tolerance Infrastructure. They can propagate their fault information to an application-specific Fault Analyzer through the Fault Notifier provided by the infrastructure. The Fault Analyzer can interpret these application-specific fault reports, generate reports that can be understood by the Replication Manager, and propagate them to the Replication Manager through the Fault Notifier, as shown in Figure 23-8.
• Statically Deployed Fault Detectors. In an operating environment with a relatively static configuration, location-specific Fault Detectors will typically be created when the Fault Tolerance Infrastructure is installed. For example, these stand-alone Fault
Detectors could be implemented as daemon processes that are installed with the Fault Tolerance Infrastructure. These Fault Detectors could be registered in a manner internal to the Fault Tolerance Infrastructure, allowing the infrastructure to include them in every fault-tolerant application within the fault tolerance domain in a transparent manner.