| Previous | Table of Contents | Next |
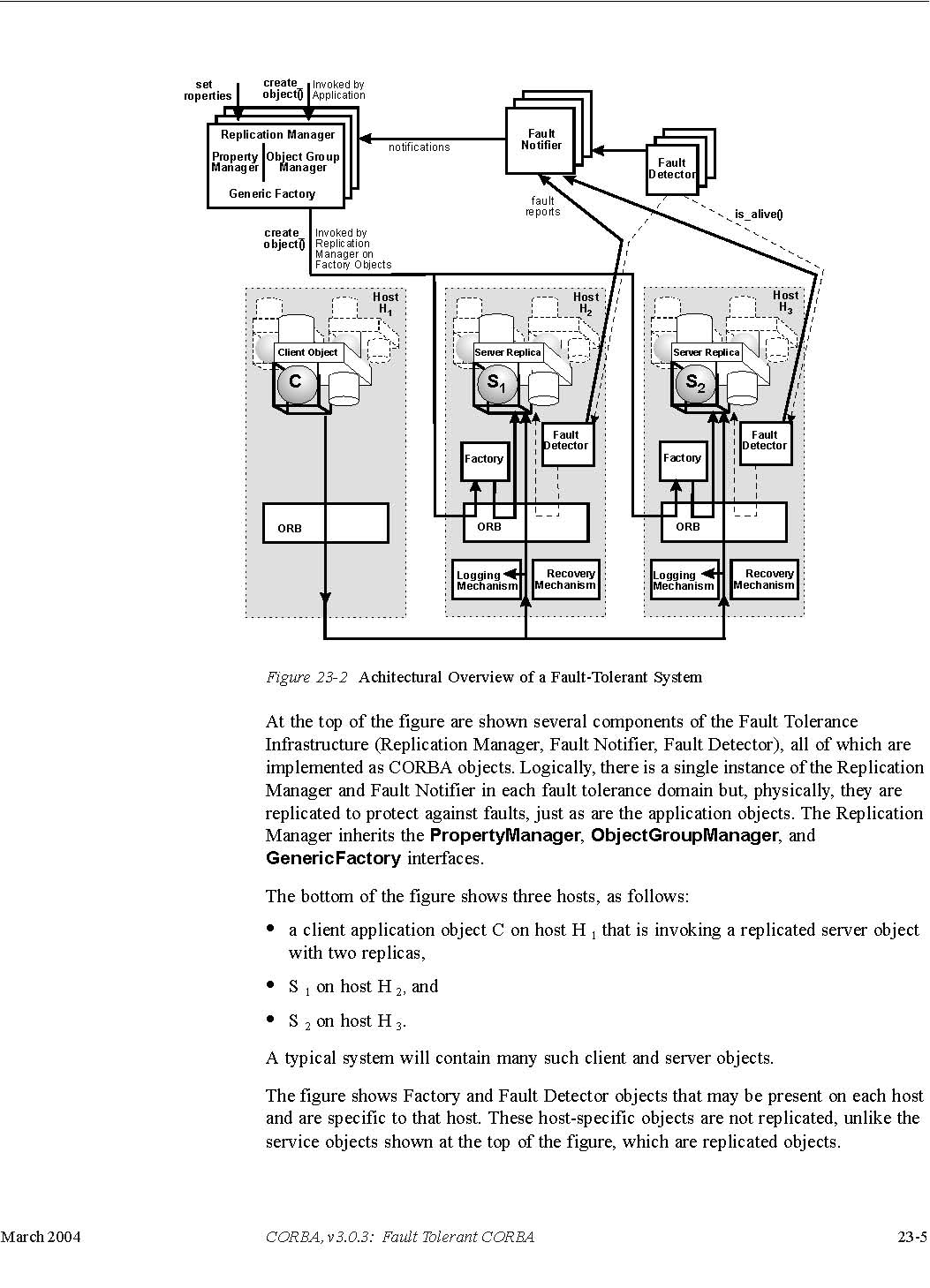
Figure 23-2 presents an architectural overview of a fault-tolerant system, showing an
example strategy for implementation of the specifications for Fault Tolerant CORBA. Other implementation strategies are possible.
set create_ Invoked by roperties object() Application
Replication Manager Fault notifications Notifier
Property Object Group Manager Manager
Generic Factory
create_ Invoked by
object() Replication Manager on Factory Objects
Host H1
FaultDetector
fault reports is_alive()
Host Host H2 H3
Client Object Server Replica Server Replica
CS1 S2
Fault Fault Detector Detector Factory Factory
ORB ORB ORB
Logging Recovery Logging Recovery Mechanism Mechanism Mechanism Mechanism
Figure 23-2 Achitectural Overview of a Fault-Tolerant System
At the top of the figure are shown several components of the Fault Tolerance Infrastructure (Replication Manager, Fault Notifier,
Fault Detector), all of which are implemented as CORBA objects. Logically, there is a single instance of the Replication Manager
and Fault Notifier in each fault tolerance domain but, physically, they are replicated to protect against faults, just as
are the application objects. The Replication Manager inherits the PropertyManager, ObjectGroupManager, and GenericFactoryinterfaces.
The bottom of the figure shows three hosts, as follows:
• a client application object C on host H 1that is invoking a replicated server object with two replicas,
• S 1on host H 2, and
• S 2on host H 3.
A typical system will contain many such client and server objects.
The figure shows Factory and Fault Detector objects that may be present on each host and are specific to that host. These
host-specific objects are not replicated, unlike the service objects shown at the top of the figure, which are replicated
objects.
The figure also shows the Message Handler and the Logging and Recovery Mechanisms that are present on each host. These are
not CORBA objects but, rather, are a part of the ORB, or are located between the ORB and the operating system.
23.1.4.1 Fault Tolerance Property Management
This specification provides a PropertyManager interface that allows the user to define fault tolerance properties of object
groups. The specification of the PropertyManager interface is designed to allow vendors to develop graphical user interfaces
and to define additional properties should they so desire.
Two properties of particular relevance are the Membership Style and the Consistency Style. The Membership Style defines whether
the membership of an object group is infrastructure-controlled or application-controlled. Similarly, the Consistency Style
defines whether the consistency of the states of the members of an object group is infrastructure-controlled or application-controlled.
Some components of the Fault Tolerance Infrastructure, such as the Logging and Recovery Mechanisms, are used only for object
groups that have the infrastructure-controlled Consistency Style.
23.1.4.2 Replication Management
For the infrastructure-controlled (MEMB_INF_CTRL) Membership Style (
Section 23.3.2.2, “MembershipStyle,? on page 23-33) the replication of objects is
substantially transparent to the application program, which simplifies the development of new application programs, and allows
the continued use of existing application programs.
Using the create_object() operation of the GenericFactory interface, the application program requests the creation of a replicated
object (object group), just as it would an unreplicated object. This operation is invoked on the Replication Manager, rather
than directly on the factory (as it would have been in the unreplicated case). The Replication Manager then invokes the factories,
on the different hosts, where a replica is to be created, using the same create_object() operation of the GenericFactory interface.
Using the create_member(), add_member(), and remove_member() operations of the ObjectGroupManager interface, the application
can exercise control over the addition and removal, and location, of members of an object group (violating transparency).
While each individual replica has its own object reference, the object group as a whole has its interoperable object group
reference, which is created by the Replication Manager. This object group reference contains a TAG_FT_GROUP component for
the object group within the profiles of the object group reference. The object group reference is returned to the application
by the Replication Manager, and is published by the server object. The client objects use the object group reference to invoke
methods on the server object group, just as they would have used a conventional object reference for an unreplicated object.
Because of the object group abstraction, the client objects are not aware that the server objects are replicated (client transparency
to replication), and are not aware of faults in the server replicas or of the recovery of server replicas when a fault has
occurred (client transparency to faults).
23.1.4.3 Fault Detection and Notification
Fault tolerance requires fault detection, and typical systems contain several fault detection mechanisms to detect host failures,
resource exhaustion, etc. This specification defines a simple PullMonitorable interface that the application objects inherit.
The PullMonitorable interface contains the is_alive() operation that a Fault Detector invokes. For efficiency, the Fault Detector
that monitors an application object is typically located on the same host as that object, while the local Fault Detectors
are monitored by a global Fault Detector that is replicated for fault tolerance.
The Fault Detector, and other kinds of fault detectors in the system, such as those based on the PUSH Monitoring Style and
those that detect host or network faults, report faults to the Fault Notifier, which passes fault notifications to the Replication
Manager and other objects that have registered for such notifications. An application-specific fault analyzer may register
to receive such notifications, and may condense and filter such notifications into further fault reports that it returns to
the Fault Notifier.
23.1.4.4 Logging and Recovery
For the COLD_PASSIVE and WARM_PASSIVE Replication Styles, under fault-free conditions, only one member of an object group,
the primary member, executes the requests and generates the replies. If the Fault Detector suspects that the primary member
is faulty, the Replication Manager, at its discretion, restarts the current primary member or promotes a backup member to
become the new primary member.
For the application-controlled (CONS_APP_CTRL) Consistency Style, the Replication Manager takes no further recovery action
and the new primary member is responsible for the recovery of its own state.
For the infrastructure-controlled (CONS_INF_CTRL) Consistency Style, the new primary member must start operation with the
appropriate state, and must execute the same sequence of requests that were, or should have been, executed by the previous
primary member, had it not failed. Thus, each GIOP message is passed to the Logging and Recovery Mechanisms, automatically
and invisibly to the application. The Logging Mechanism records the message in a log, from which the Recovery Mechanism can
retrieve the message during recovery.
Periodically, the Logging Mechanism invokes the get_state() operation of the Checkpointable interface, which must be implemented
by every replicated application object, to obtain the state of the object, so that the state can be recorded in a log. During
recovery, the Recovery Mechanism invokes the set_state() operation of the Checkpointable interface of the new primary to set
its state to the state that was recorded in the log.