| Previous | Table of Contents | Next |
13.10.2.1 Requirements
The file code set that an application uses is often determined by the platform on which it runs. In Japan, for example, Japanese
EUC is used on Unix systems, while Shift-JIS is used on PCs. Code set conversion is therefore required to enable interoperability
across these platforms. This proposal defines a framework for the automatic conversion of code sets in such situations. The
requirements of this framework are:
1. Backward compatibility. In previous CORBA specifications, IDL type char was limited to ISO 8859-1. The conversion framework should be compatible with existing clients and servers that use ISO 8859-1 as the code set for char.
2. Automatic code set conversion. To facilitate development of CORBA clients and servers, the ORB should perform any necessary code set conversions automatically and efficiently. The IDL type octet can be used if necessary to prevent conversions.
3. Locale support. An internationalized application determines the code set in use by examining the LOCALE string (usually found in the LANG environment variable), which may be changed dynamically at run time by the user. Example LOCALE strings are fr_FR.ISO8859-1 (French, used in France with the ISO 8859-1 code set) and ja_JP.ujis (Japanese, used in Japan with the EUC code set and X11R5 conventions for LOCALE). The conversion framework should allow applications to use the LOCALE mechanism to indicate supported code sets, and thus select the correct code set from the registry.
4. CMIR and SMIR support. The conversion framework should be flexible enough to allow conversion to be performed either on the client or server side. For example, if a client is running in a memory-constrained environment, then it is desirable for code set converters to reside in the server and for a Server Makes It Right (SMIR) conversion method to be used. On the other hand, if many servers are executed on one server machine, then converters should be placed in each client to reduce the load on the server machine. In this case, the conversion method used is Client Makes It Right (CMIR).
13.10.2.2 Overview of the Conversion Framework
Both the client and server indicate a native code set indirectly by specifying a locale. The exact method for doing this is
language-specific, such as the XPG4 C/C++ function setlocale. The client and server use their native code set to communicate
with their ORB. (Note that these native code sets are in general different from process code sets and hence conversions may
be required at the client and server ends.)
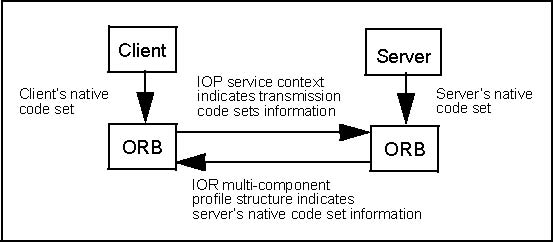
The conversion framework is illustrated in Figure 13-7. The server-side ORB stores a
server’s code set information in a component of the IOR multiple-component profile
structure (see Section 13.6.2, “Interoperable Object References: IORs? on page
13-14
)1. The code sets actually used for transmission are carried in the service context
field of an IOP (Inter-ORB Protocol) request header (see Section 13.7, “Service
Context? on page 13-28 and Section 13.10.2.5, “GIOP Code Set Service Context? on
page 13-44). Recall that there are two code sets (TCS-C and TCS-W) negotiated for
each session.
1. Version 1.1 of the IIOP profile body can also be used to specify the server’s code set information, as this version introduces
an extra field that is a sequence of tagged components.
Figure 13-7 Code Set Conversion Framework Overview
If the native code sets used by a client and server are the same, then no conversion is performed. If the native code sets
are different and the client-side ORB has an appropriate converter, then the CMIR conversion method is used. In this case,
the server’s native code set is used as the transmission code set. If the native code sets are different and the client-side
ORB does not have an appropriate converter but the server-side ORB does have one, then the SMIR conversion method is used.
In this case, the client’s native code set is used as the transmission code set.
The conversion framework allows clients and servers to specify a native char code set and a native wchar code set, which determine
the local encodings of IDL types char and wchar, respectively. The conversion process outlined above is executed independently
for the char code set and the wchar code set. In other words, the algorithm that is used to select a transmission code set
is run twice, once for char data and once for wchar data.
The rationale for selecting two transmission code sets rather than one (which is typically inferred from the locale of a process)
is to allow efficient data transmission without any conversions when the client and server have identical representations
for char and/or wchar data. For example, when a Windows NT client talks to a Windows NT server and they both use Unicode for
wide character data, it becomes possible to transmit wide character data from one to the other without any conversions. Of
course, this becomes possible only for those wide character representations that are well-defined, not for any proprietary
ones. If a single transmission code set was mandated, it might require unnecessary conversions. (For example, choosing Unicode
as the transmission code set would force conversion of all byte-oriented character data to Unicode.)
13.10.2.3 ORB Databases and Code Set Converters
The conversion framework requires an ORB to be able to determine the native code set for a locale and to convert between code
sets as necessary. While the details of exactly how these tasks are accomplished are implementation-dependent, the following
databases and code set converters might be used:
• Locale database. This database defines a native code set for a process. This code set could be byte-oriented or non-byte-oriented and could be changed programmatically while the process is running. However, for a given session between a client and a server, it is fixed once the code set information is negotiated at the session’s setup time.
• Environment variables or configuration files. Since the locale database can only indicate one code set while the ORB needs to know two code sets, one for char data and one for wchar data, an implementation can use environment variables or configuration files to contain this information on native code sets.
• Converter database. This database defines, for each code set, the code sets to which it can be converted. From this database, a set of “conversion code sets? (CCS) can be determined for a client and server. For example, if a server’s native code set is eucJP, and if the server-side ORB has eucJP-to-JIS and eucJP-to-SJIS bilateral converters, then the server’s conversion code sets are JIS and SJIS.
• Code set converters. The ORB has converters which are registered in the converter database.
13.10.2.4 CodeSet Component of IOR Multi-Component Profile
The code set component of the IOR multi-component profile structure contains:
• server’s native char code set and conversion code sets, and
• server’s native wchar code set and conversion code sets.
Both char and wchar conversion code sets are listed in order of preference. The code set component is identified by the following
tag:
const IOP::ComponentID TAG_CODE_SETS = 1;
This tag has been assigned by OMG (See Section 13.6.6, “Standard IOR Components?
on page 13-19.). The following IDL structure defines the representation of code set
information within the component:
module CONV_FRAME { // IDL typedef unsigned long CodeSetId; struct CodeSetComponent {
CodeSetId native_code_set;
sequence<CodeSetId> conversion_code_sets; }; struct CodeSetComponentInfo {
CodeSetComponent ForCharData;CodeSetComponent ForWcharData;};};
Code sets are identified by a 32-bit integer id from the OSF Character and Code Set
Registry (See Section 13.10.5.1, “Character and Code Set Registry? on page 13-50 for
further information). Data within the code set component is represented as a structure of type CodeSetComponentInfo, and is
encoded as a CDR encapsulation. In other words, the char code set information comes first, then the wchar information, represented
as structures of type CodeSetComponent.
A null value should be used in the native_code_set field if the server desires to indicate no native code set (possibly with
the identification of suitable conversion code sets).
If the code set component is not present in a multi-component profile structure, then the default char code set is ISO 8859-1
for backward compatibility. However, there is no default wchar code set. If a server supports interfaces that use wide character
data but does not specify the wchar code sets that it supports, client-side ORBs will raise exception INV_OBJREF, with standard
minor code 1.
If a client application invokes an operation which results in an attempt by the client ORB to marshal wchar or wstring data
for an in parameter (or to unmarshal wchar or wstring data for an in/out parameter, out parameter or the return value), and
the associated Object Reference does not include a codeset component, then the client ORB shall raise the INV_OBJREF standard
system exception with standard minor code 2 as a response to the operation invocation.
13.10.2.5 GIOP Code Set Service Context
The code set GIOP service context contains:
• char transmission code set, and
• wchar transmission code set
in the form of a code set service. This service is identified by:
const IOP::ServiceID CodeSets = 1;
The following IDL structure defines the representation of code set service information:
module CONV_FRAME { // IDL typedef unsigned long CodeSetId; struct CodeSetContext {
CodeSetId char_data;CodeSetId wchar_data;};};
Code sets are identified by a 32-bit integer id from the OSF Character and Code Set
Registry (See Section 13.10.5.1, “Character and Code Set Registry? on page 13-50 for
further information).
Note – A server’s char and wchar Code set components are usually different, but under some special circumstances they can
be the same. That is, one could use the same code set for both char data and wchar data. Likewise the CodesetIds in the service
context don’t have to be different.
13.10.2.6 Code Set Negotiation
The client-side ORB determines a server’s native and conversion code sets from the code set component in an IOR multi-component
profile structure, and it determines a client’s native and conversion code sets from the locale setting (and/or environment
variables/configuration files) and the converters that are available on the client. From this information, the client-side
ORB chooses char and wchar transmission code sets (TCS-C and TCS-W). For both requests and replies, the char TCS-C determines
the encoding of char and string data, and the wchar TCS-W determines the encoding of wchar and wstring data.
Code set negotiation is not performed on a per-request basis, but only when a client initially connects to a server. All text
data communicated on a connection are encoded as defined by the TCSs selected when the connection is established.
Figure 13-8 illustrates, there are two channels for character data flowing between the
client and the server. The first, TCS-C, is used for char data and the second, TCS-W, is used for wchar data. Also note that
two native code sets, one for each type of data, could be used by the client and server to talk to their respective ORBs (as
noted earlier, the selection of the particular native code set used at any particular point is done via setlocale or some
other implementation-dependent method).
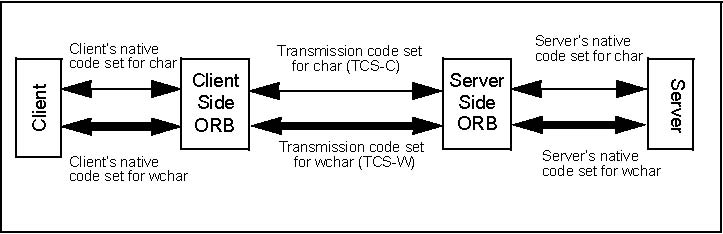
Figure 13-8 Transmission Code Set Use
Let us look at an example. Assume that the code set information for a client and server is as shown in the table below. (Note
that this example concerns only char code sets and is applicable only for data described as chars in the IDL.)
Client |
Server |
||||
| Native code set: | SJIS | eucJP | |||
| Conversion code sets: | eucJP, JIS | SJIS, JIS |
The client-side ORB first compares the native code sets of the client and server. If they are identical, then the transmission
and native code sets are the same and no conversion is required. In this example, they are different, so code set conversion
is necessary. Next, the client-side ORB checks to see if the server’s native code set, eucJP, is one of the conversion code
sets supported by the client. It is, so eucJP is selected as the transmission code set, with the client (i.e., its ORB) performing
conversion to and from its native code set, SJIS, to eucJP. Note that the client may first have to convert all its data described
as chars (and possibly wchar_ts) from process codes to SJIS first.
Now let us look at the general algorithm for determining a transmission code set and where conversions are performed. First,
we introduce the following abbreviations:
• CNCS - Client Native Code Set;
• CCCS - Client Conversion Code Sets;
• SNCS - Server Native Code Set;
• SCCS - Server Conversion Code Sets; and
• TCS - Transmission Code Set.
The algorithm is as follows:
if (CNCS==SNCS) TCS = CNCS; // no conversion required else { if (elementOf(SNCS,CCCS)) TCS = SNCS; // client converts to server’s
native code set else if (elementOf(CNCS,SCCS)) TCS = CNCS; // server converts from client’s native code set
else if (intersection(CCCS,SCCS) != emptySet) {
TCS = oneOf(intersection(CCCS,SCCS));
// client chooses TCS, from intersection(CCCS,SCCS), that is
// most preferable to server;
// client converts from CNCS to TCS and server
// from TCS to SNCS
else if (compatible(CNCS,SNCS)) TCS = fallbackCS; // fallbacks are UTF-8 (for char data) and // UTF-16 (for wchar data) else
raise CODESET_INCOMPATIBLE exception; }
The algorithm first checks to see if the client and server native code sets are the same. If they are, then the native code
set is used for transmission and no conversion is required. If the native code sets are not the same, then the conversion
code sets are examined to see if
1. the client can convert from its native code set to the server’s native code set,
2. the server can convert from the client’s native code set to its native code set, or
3. transmission through an intermediate conversion code set is possible.
If the third option is selected and there is more than one possible intermediate conversion code set (i.e., the intersection
of CCCS and SCCS contains more than one code set), then the one most preferable to the server is selected.2
If none of these conversions is possible, then the fallback code set (UTF-8 for char data and UTF-16 for wchar data— see below)
is used. However, before selecting the fallback code set, a compatibility test is performed. This test looks at the character
sets encoded by the client and server native code sets. If they are different (e.g., Korean and French), then meaningful communication
between the client and server is not possible and a CODESET_INCOMPATIBLE exception is raised. This test is similar to the
DCE compatibility test and is intended to catch those cases where conversion from the client native code set to the fallback,
and the fallback to the server native code set
would result in massive data loss. (See Section 13.10.5, “Relevant OSFM Registry
Interfaces? on page 13-50 for the relevant OSF registry interfaces that could be used
for determining compatibility.)
A DATA_CONVERSION exception is raised when a client or server attempts to transmit a character that does not map into the
negotiated transmission code set. For example, not all characters in Taiwan Chinese map into Unicode. When an attempt is made
to transmit one of these characters via Unicode, an ORB is required to raise a DATA_CONVERSION exception, with standard minor
code 1.
In summary, the fallback code set is UTF-8 for char data (identified in the Registry as 0x05010001, “X/Open UTF-8; UCS Transformation
Format 8 (UTF-8)"), and UTF-16 for wchar data (identified in the Registry as 0x00010109, "ISO/IEC 10646-1:1993; UTF-16, UCS
Transformation Format 16-bit form"). As mentioned above the fallback code set is meaningful only when the client and server
character sets are compatible, and the fallback code set is distinguished from a default code set used for backward compatibility.
If a server’s native char code set is not specified in the IOR multi-component profile, then it is considered to be ISO 8859-1
for backward compatibility. However, a server that supports interfaces that use wide character data is required to specify
its native wchar code set; if one is not specified, then the client-side ORB raises exception INV_OBJREF, with standard minor
code set to 1.
Similarly, if no char transmission code set is specified in the code set service context, then the char transmission code
set is considered to be ISO 8859-1 for backward compatibility. If a client transmits wide character data and does not specify
its wchar transmission code set in the service context, then the server-side ORB raises exception BAD_PARAM, with standard
minor code set to 23.
To guarantee “out-of-the-box? interoperability, clients and servers must be able to convert between their native char code
set and UTF-8 and their native wchar code set (if specified) and Unicode. Note that this does not require that all server
native code sets be mappable to Unicode, but only those that are exported as native in the IOR. The server may have other
native code sets that aren’t mappable to Unicode and those can
2.Recall that server conversion code sets are listed in order of preference.
be exported as SCCSs (but not SNCSs). This is done to guarantee out-of-the-box interoperability and to reduce the number of
code set converters that a CORBA-compliant ORB must provide.
ORB implementations are strongly encouraged to use widely-used code sets for each regional market. For example, in the Japanese
marketplace, all ORB implementations should support Japanese EUC, JIS and Shift JIS to be compatible with existing business
practices.