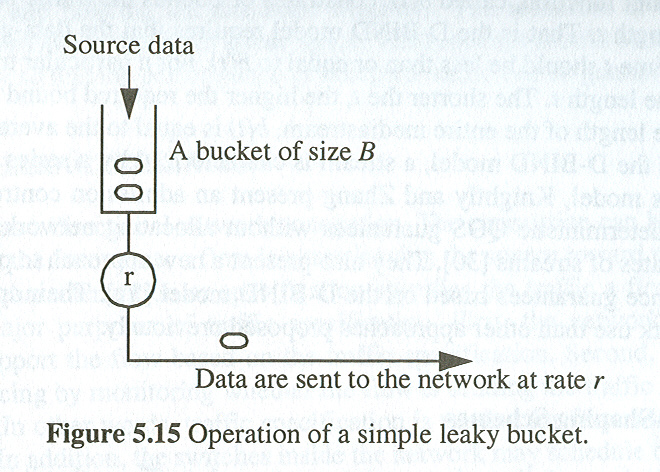
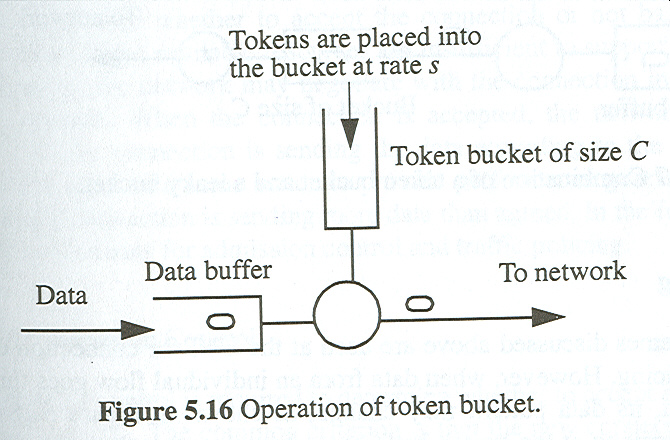
In many cases, the throughput required by an application is not constant, but variable (e.g. compressed video). This is called vaiable bit rate. People have designed various ways to characterize the variable throughput of applications (traffic characterization), using traffic models based on a leaky bucket or token bucket (see [Lu, Sect. 5.7 through 5.9]).
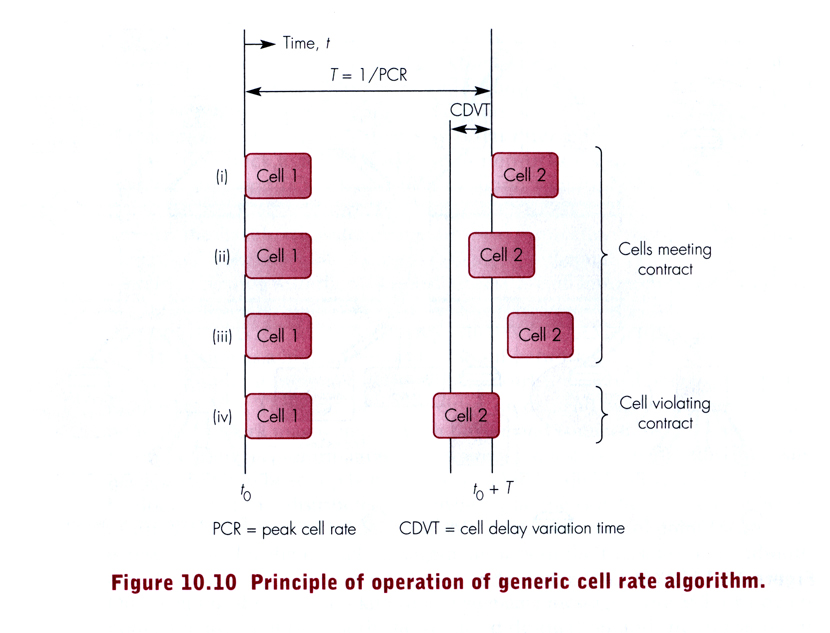
In the context of ATM, various classes of traffic have been defined, as well as the QoS parameters provided by an ATM network, which may be negotiated for each new ATM connection (see slides S1 , S2 , S3 ; for more details, see Chapters 6 on "QoS and ATM" in [Ferg 98] P. Ferguson and G. Huston, Quality of Service - Delivering QoS on the Internet and in Corporate Networks, John Wiley, 1998).
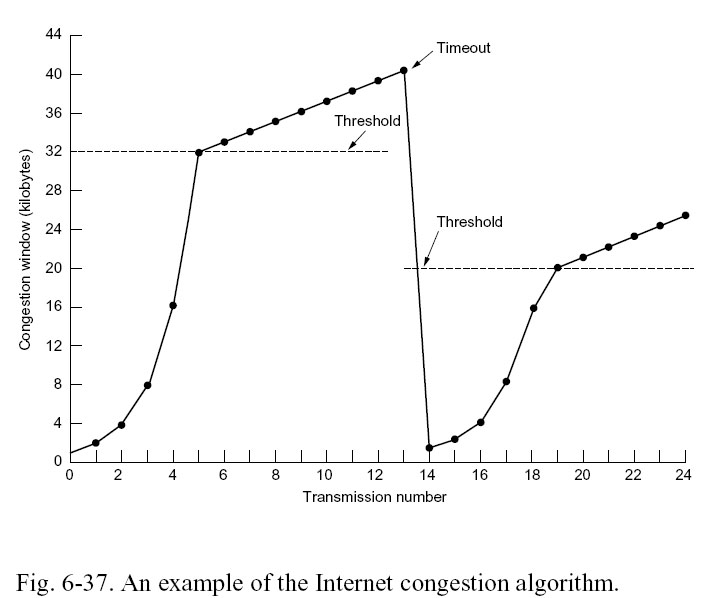
A so-called congestion window is introduced that limits the size of the transmission window, it has initially the value of one maximum segment size. Slow start has two stages. The first stage is actually not "slow": when all packets corresponding to one congestion window have been acknowledged, the window is doubled. When the window reaches the congestion threshold (initially set to 64Koctets), then the window is increased each time only by one maximum segment size (this stage is "slow"). However, when a packet is lost, that is no acknowledgement is received for a given packet for a certain time-out period, the slow start process starts again, but the threshold is set to half the last value of the congestion window. If there is a bottleneck in the network, all TCP connections routing their packet through that bottleneck will have a certain probability of having packet losses, and will therefore drastically reduce their throughput. This will alleviate the congestion status of that bottleneck (see example from Tanenbaum's book).
"TCP friendliness" means that UDP traffic is "friendly" with TCP traffic, that is, if there are losses, UDP traffic will also reduce its bandwidth for an amount similar to what TCP traffic would do. This means that there is no unfair competition between TCP and UDP traffic. Without this "TCP friendliness", UDP traffic would continue sending packets independently of the loss rate; as a result, the congestion will probably remain and the TCP traffic will be largely reduced, while the UDP traffic continues (possibly with unacceptable loss rate).
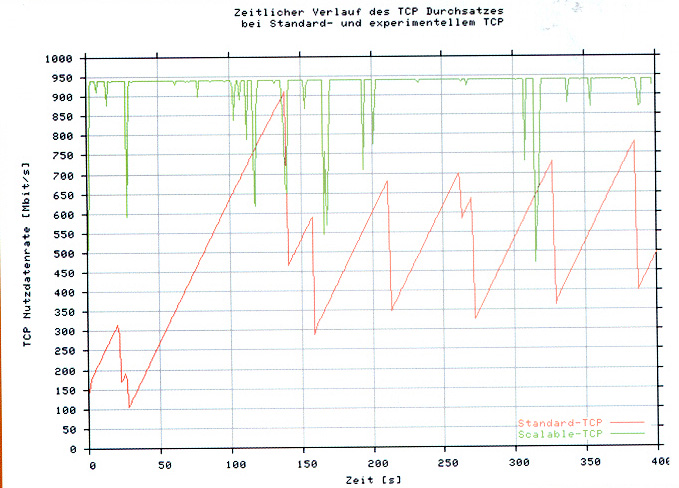
The standard congestion management feature of TCP does not work well at very high transmission bandwidth. Therefore various modifications to TCP have been proposed to make it suitable for hish-speed grid computing. One of these proposals is "Scalable TCP". A comparison of normal and scalable TCP was presented in the "DFN Mitteilungen" (March 2004) for some particular Grid session in Europe (note: the value 1000 corresponds to the available bandwidth in this example).
In the future, two approaches for providing some choices to applications are foreseen (for more details, see paper by Xiao ):
Here are some interesting further readings, which are not part of the official course content, relating to possible future developments of the Internet:
In a network, the forwarding tables at all switching nodes must be established in such a manner that the blocks of data are sent along the switched connections that are established end-to-end through the network. When a new connection is established, the tables along the path of that connection are updated accordingly. All data over a given connection follows the same path which is determined when the connection is established.
The path for a new connection is either determined by a routing algorithm executed in a central control unit which then signals the forwarding table updates to each node, or it is determined in a distributed manner, usually through a signalling protocol which forwards a connection establishment request from one node to the next and each node determines the next hop of the connection path by looking up the best choice in a local routing table. The establishment of these routing table is a matter for a distributed routing protocol.
The switching function is very similar in the case of ATM switching, MPLS
(Multi-Protocol Label Switching), and and so-called Lambda Switching used
for Dense Wavelength Multiplexing (DWDM) in optical networks. Here is a correspondence:
| Technology | Unit of data processed | Channel characterization | method for updating forwarding tables in the nodes of the network | method for determining the end-to-end routes realized by the forwarding tables |
| Time-division multiplexing | block | time unit in which block is received / sent | SS7 signaling protocol | |
| ATM switching | cell (56 octets) | virtual path and virtual circuit identifiers in cell header | PNNI signaling protocol | PNNI routing protocol |
| MPLS | packet | value of the label added to the packet | Label Distribution Protocol (LSP) or RSVP-TE (adaptation of RSVP) | IP routing protocol (e.g. OSPF, BGP, etc.) |
| Lambda Switching | modulated lightflow | wavelength of lightflow | different proposals (GMPLS with LSP or RSVP-TE, OBGP, etc.) | |
| Optical space switching | all light within one fiber | physical fiber port | different proposals |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}