[ PDF ]
Web crawlers (sometimes called Web robots, Web spiders or Wanderers) are programs that automatically traverse the Internet to gather information. Search engines, such as Google, build up their content using such programs; Googlebot, in the case of Google. Simply, a Web crawler starts at an arbitrary Web page, stores all the links that are found in that page, then starts again from a different location, i.e. takes one link from the collection of saved links, gets the content of that page, extracts and stores all the links, and starts over from a different location. In doing so, its collection of links grows and eventually all the available Web pages are visited. In the case of a Web crawler for a search engine, when a page is visited, information about the content of the page is also stored, for example, to build up an index associating words such as “assignment”, “deadline” and “crawlers” with the link that corresponds to this Web page.
Documents on the Web are generally stored in a format called HTML (HyperText Markup Language). Links between the pages are also represented in a standard way. A Uniform Resource Locator (URL) is a standard way to represent the address of a Web page on Internet and this is used to create links between Web pages.
For this assignment, you will be implementing a Web crawler to determine if a path exists in between two Web pages; let’s define a path as an ordered sequence of URLs such that each Web page of the sequence has a link (URL) to the next Web page of the sequence. Your implementation will use the breadth-first search algorithm presented in class and therefore will also find the shortest path!
The class HTML represents a Web document. Its constructor takes as input the url of the page to be represented in your program.
An HTML document has a method hasMoreURLs() as well as a method nextURL(). The method hasMoreURLs returns true if the page has more links that have not yet been returned by the method nextURL. Each call to the method nextURL returns the next URL found in this page. The method nextURL throws an exception of type NoSuchElementException if there are no next link. Therefore, each call must be preceded by a call to hasMoreURLs. The typical usage is as follows.
The breadth-first search algorithm, implemented by the class Crawler, incrementally builds all the valid paths, from the shortest to the longest paths. Each path represents a partial solution to our problem (finding a valid path from page A to page B). An object of the class Path is used to represent a partial solution. Write an implementation of the class Path according to the following specification.
The following example shows the intended use of this class. An initial solution, designated by a, is created that contains one URL. A second solution is created from a, that extends the path by one URL, then a third solution is created from b, always extending the path of an existing solution by one URL.
the above statement would print this,
and
would print this,
The class Crawler contains three static methods that are used to find a path from a Web page A to a Web page B; it is also possible that no such path exists. The method solve implements the breadth-first search algorithm presented in class.
The method isValid returns true if url is a well formed URL designating an existing and readable Web page, and false otherwise. In order to implement this method, you can use the fact that the constructor of an HTML object i) throws an exception, of type MalformedURLException, if the url is not well formed, and ii) throws an exception, of type IOException, if the content of the page cannot be successfully read.
You must implement a breadth-first search algorithm for finding a path from a Web page A to a Web page B. The breadth-first search uses a Queue data structure (LinkedQueue).
To briefly summarize what was said in class, “breadth-first search” uses a queue to generate all the sequences in increasing order of length. Each element of the queue is a partial solution (an object of the class Path). The algorithm initializes the queue to contain a partial solution that consists of the Web page A, and repeatedly does the following:
Your method should return as soon as a solution is found, and it should not put into the queue paths that are not “valid”. A path is not valid if it contains a non-valid URL or it contains cycles (a path that visits the same URL more than once. Hint: this is what contains is for). You can test that a URL is valid by calling the method isValid. If you know that a path is valid you can check if it is a solution by comparing its last URL to the URL of the Web page B.
The main method prints the following message unless there are exactly two arguments on the command line, and exists immediately.
If the command line has two arguments, those arguments are used for calling the method solve. The main method prints the path if it exists, and “no path” if no such path was found.
You will find several examples at the following URL:
Here is an example of a run.
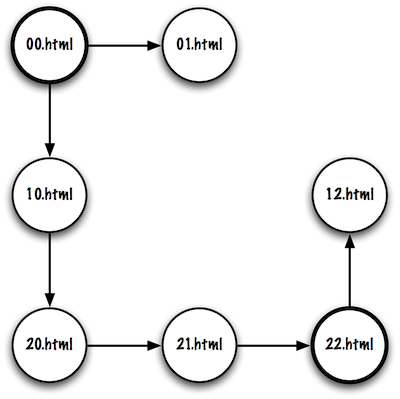
Note. The two URLs should be typed on the same line. Example 1 has a set of Web pages that represent the following Maze.
the page 00.html represents the upper left corner, it has two links, one to the page 01.html and the other to the page 10.html. As you can see, the name of the page represents the coordinates of the cell within the labyrinth.
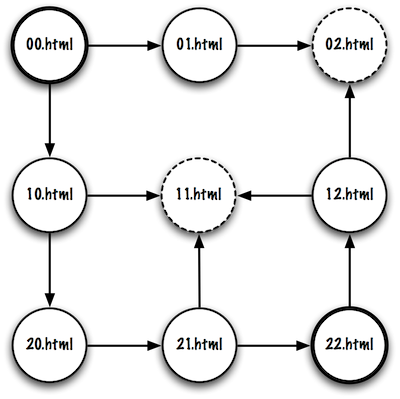
Example 2 also represents a maze, but it contains invalid URLs (represented by the dashed circles). For each example, you can generate several test cases by selecting different starting points (Web pages). You can experiment with these examples using your Web browser. Example 3 represents a maze that has pages on three Web servers:
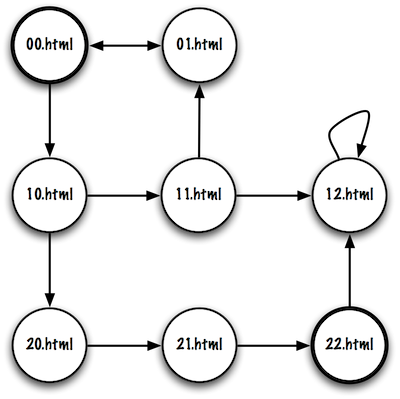
Example 4 contains cycles, i.e. certain paths visit the same page more than one.
True or False. It is possible to implement a stack and a queue in such a way that all the operations take a constant amount of time.
Last Modified: March 12, 2014