SEG-2106 "Software Construction"
Chapter 3-1: Concurrency
Additional readings:
- [Sebesta] chapter 12 (see printed course notes) Please read Sebesta 12.1 (Introduction), 12.2
(Introduction to subprogram-level concurrency), 12.3 (Semaphores), 12.4
(Monitors), and 12.7 (Java threads).
Hardware and software concurrency
Physical concurrency
A single CPU of a computer executes one instruction after the
other. There is no concurrency. If we have several CPUs running
in parallel (either within the same computer or in separate
computers) we have some form of concurrency (also called
parallelism). Concurrency realized at the hardware level is
called physical concurrency. Physical concurrency is related to
parallel computer architectures:
- A normal computer contains at least one CPU and several peripharel processing units that look after input/output with the external world, such as video display, sound input and output, disc access, etc. Also the computer clock is a separate hardware unit that runs concurrently with the CPU and is used to control the scheduler of the operating system which allocates time slots to the different programs running on the computer (see below).
- Various schemes have been
designed to build hardware architectures with multiple CPUs. The purpose is to
efficiently execute various computing tasks in parallel. They
can be classified as follows:
- SIMD (single instruction - multiple data): These are
computers where multiple CPUs work on different data, but
all execute the same sequence of instructions. Vector
processors belong to this class.
- MIMD (multiple instructions - multiple data): Here the
different CPUs execute different sequences of
instructions (and work on different sets of data). They
can be further classified as
- shared memory architectures: Here all CPUs
access the same memory (it is easy to share
data between the different processes executed
by the CPUs)
- distributed architectures: Here each CPU has
its own (local) memory (in a sense, each CPU
is a more or less complete computer); sharing
of data between the processes executed by the
different CPUs is less efficient (usually
realized through some network through which
the different CPUs are connected.
- Concurrency at the level of instruction execution: This is realized when a single
CPU, which consists of several parallel operating
components, is organized in such a way that several
instructions to be executed are processed in parallel,
usually in some form of pipeline processing where each
instruction goes through the different components each
doing specific aspects of the instruction processing - such as (1) fetching the next instruction, (2) feching the operands, (3) performing an arithmetic operation.
Concurrency in software
The book by Sebesta mentions the following levels of
concurrency:
- Instruction concurrency: this is actually concurrency at the hardware level, called "Concurrency at the level of instruction execution" above.
- Statement concurrency: This means that several statements
of a program are executed concurrently on some physical
parallel computer architecture. Usually, one considers a
conventional (sequential - non-concurrent) programming
language, such as Fortran or C. Certain optimizing
compilers can automatically determine which statements
are independent of one another and can be executed
concurrently without changing the result of the program
execution. They can also take the existing parallel
hardware architecture into account (on which the program
is supposed to be executed) in order to generate code for
this hardware architecture which provides for concurrent
statement execution. Note: The programmer is normally not much involved for this kind of concurrency, since it is dealt with automatically by the optimizing compiler.
- Unit (or sub-program) concurrency: Here one talks about concurrent
"units", which are defined by the programming
language and are intended to be executed concurrently.
Programming languages with concurrent "units"
allow the programmer to design programs which include a
number of concurrent activities and the concurrency
structure of a program depends very much on the
application. A typical application area where concurrent
"units" are very useful is simulation of
process control or transportation systems, where the
simulated objects evolve in real time concurrently. This
level of concurrency is also called logical concurrency.
In contrast to physical concurrency, it does not imply
that the logically concurrent "units" are
really executed in physical concurrency. Often they are
executed in an interleaved manner (time-sharing, see
below). Note: Instead of "unit", one often uses
the words process, thread, task, or simply concurrent
statements. Note: This kind of concurrency must be understood by the programmer that uses the programming language that supports concurrent threads (e.g. Java). In this course, we are mainly interested in this kind of concurrency.
- Program (or task) concurrency: Often several programs are executed
concurrently (in an interleaved manner) on a computer
within a time-sharing operating system. The CPU of the
computer is shared among the programs by allocating the
CPU to each program for a short time slice at a time. The
allocation is done by a scheduler (see Sebesta's book).
The same technique of time sharing is usually also used
for realizing concurrent "units" within a given
program (see above).
The sharing of a CPU among several concurrent threads or programs: Each operating system has a scheduler which allocates short time periods of the CPU to the different active programs running on the computer. At the end of such a time period, it determines which program should obtain the CPU in the next time period. A similar schedule is included in each program that supports several concurrent threads - this thread scheduler will determine how the time period, allocated by the operating system scheduler to the program, is shared among the threads within that program. For instance, the program running a Java JM has a scheduler to share the CPU among the threads of the Java program (if it contains threads in addition to the main thread).
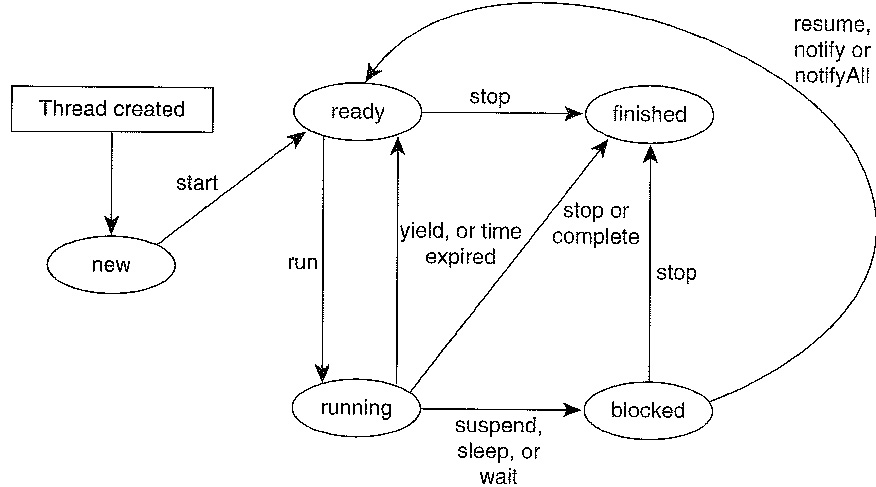
Note that the behavior of a scheduler is not always defined at all levels of details; e.g. for the Thread scheduler in a Java virtual machine, not all aspects are defined. Normally, one distinguishes the following states for a process (thread, task, ...) that is scheduled by the scheduler (see diagram below):
- New: the process was just created
- Running: the process is allocated to a processor (e.g. CPU) that executes the instructions of the process
- Ready: the process is ready to be executed, but no processor is available. When a processor terminates the execution of a process (either because the time unit has elapsed, or the process has to wait for some input/output operation to terminate) the processor will select another process from the "ready queue" to be executed. If there are several processes waiting in the ready state, it may not be defined which one will be selected, although priorities (if defined) must be taken into account.
- Blocked: the process waits for an input/output operation to be completed before getting into the Ready state.
- Terminated: the process has no more instructions to be executed.
Dependencies between concurrent processes
Different kinds of dependencies
In the simplest case, concurrent processes perform their
processing independently from one another. But often they have to
coordinate their work, which is done through interprocess
communication and synchronization. One may classify their
interrelationship as follows:
- Disjoint processes: They are independent, no
synchronization (except, possibly, through their
time-shared execution by the same CPU; but this is not
seen at the logical level of the program which contains
these processes).
- Competitive synchronization: They are logically
independent of one another, but their share some common
resource (which is also described by the concurrent
program which contains these processes). Shared resources
usually require some relative synchronization of the
accesses performed by different processes (typical
example: readers and writers accessing a shared database).
- Cooperative synchronization: The logical structure of the
processing of one process depends on information obtained
from another process. A typical example is the
"producer - consumer" system, which often
contains a queue which passes objects (messages) from the
producer to the consumer (see the "Monitors and
concurrency in Java" topic explained in sections
12.4 and 12.7 of Sebesta's book).
Note: Competitive and cooperative synchronization and
communication can be realized through message passing primitives
or through shared variables (including some basic synchronization
primitive containing as an atomic operation the testing and
(conditional) updating of a variable. Such primitives can be
provided by an operating system for communication between
concurrently executing programs, or by the hardware of a
concurrent computer architecture. Examples of synchronization
primitives for shared variables are a machine instruction
"test and set" and the semaphore concept described in
Section 12.3 in Sebesta's book.
The non-deterministic nature of concurrent systems (remembering what we discussed in Chapter 1-3)
Concurrent processes give rise to a large number of possible interaction sequences because the execution of sequences of the different processes may be interleaved in many ways. In the case of independent concurrency (as for instance defined by parallel regions of UML State diagrams) one assumes by default that there is no interrelationship between the concurrent processes (no communication, no shared resources, nor shared variables). This has the advantage, that the behavior of each process can be analysed independently of the other processes. However, the number of possible overall execution sequences is the largest, because the actions of the different processes may be interleaved arbitrarily in the global execution trace. An example is shown in the following diagrams, where (a) and (b) represent two independent processes, defined in the form of LTSs, and (c) shows the resulting global behavior (obtained by reachability analysis - which is simple in this case). In this example, one assumes that the LTS transitions take no time, therefore the execution of two transitions of two different LTSs can be assumed to be sequential, one after the other, and when the LTS are independent and two transitions of different LTSs are enabled, then their order of execution is not determined; there is therefore some non-determinism introduced by this form of concurrency. This is called interleaving semantics.
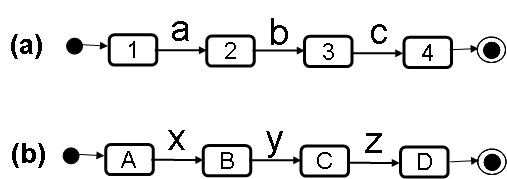
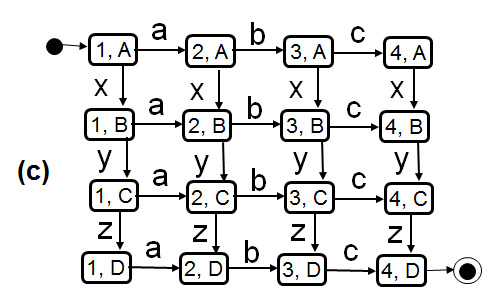
The main point is that one cannot predict which execution path will be taken by the interleaving concurrent processes. If, let us assume, there is some dependency between the two processes which leads to some possible difficulties when the transition z is taken from the global state (3, C), then it is very difficult to test the system to ensure that this dependency is correctly implemented. We cannot control the system to go through a particular path. It is worse if one does not know where a problem may reside in an implementation - the chances to execute a transition path that encounters the problem is very small indead during normal testing. Conclusion: Concurrent systems are very difficult to test for correctness. Therefore one should try to verify by logical reasoning.
Some notes on the
"message passing" concept
"Message passing" means that one process sends a
message to another process and then continues its local
processing. The message may take some time to get to the other
process and may be stored in the input queue of the destination
process if the latter is not immediately ready to receive the
message. Then the message is received by the destination process,
when the latter arrives at a point in its local processing where
it is ready to receive messages. This is called asynchronous
message passing (because sending and receiving is not at the same
time, although the reception is necessarily after the sending).
Asynchronous message passing implies the following
synchronization between the two processes:
- Blocking send and receive operations: The receive will be
blocked if it arrives at the point where it may receive
messages and no message is waiting. (The sender may get
blocked if there is no room in the message queue between
the sender and the receiver; however, in many cases, one
assumes arbitrary long queues, which means that the
sender will never be blocked).
- Non-blocking send and receive operations: In this case,
the send and receive operations always return
immediately, returning a status value which could
indicate that no message has arrived at the receiver.
Therefore the receiver may test whether a message is
waiting and possibly do some other processing.
In the case of synchronous message passing (as for instance
realized in the Ada language, see Sebesta's book, Sections 12.5.1
through 12.5.3), one assumes that sending and receiving takes
place at the same time (there is no need for an intermediate
buffer). This is also called rendezvous and implies closer
synchronization: the combined send-and-receive operation can only
occur if both parties (the sending and receiving processes) are
ready to do their part. Therefore the sending process may have to
wait for the receiving process, or the receiving process may have
to wait for the sending one (as in the case of asynchronous
message passing).
Ressource sharing
Need for mutual exclusion
- The example of two uses simulaneously updating the salaries of employees:
- One administrator increments all salaries by 5% : salary = salary * 1.05;
- The other administrator adds a 100$ bonus to employee X: salary = salary + 100;
- What are the possible outcomes for employee X, if initially he had a salary of 5000$.
- Notion of transactions in database systems (possibly distributed). A transaction must be executed completely, or not at all. Several transactions may be executed concurrently, but must follow certain scheduling rules that ensure that the net result is equivalent to serial execution (serializable schedule). A transaction must leave the database in a consistent state. In case of a system failure, the effect of partially executed transactions must be "rolled back". These properties of transactions are called ACID properties (atomicity, consistency, isolation, durability).
- Example of money transfer: Transfer of 1000$ from account A in bank BankA to account B in BankB. The transaction requires access to both accounts, residing on two different computers. It should be atomic - execute completely or be aborted (even if one of the computers fails during the operations). The mutual exclusion should include both accounts - they both must be reserved before they can be used, and later freed. - The resource for which mutually exclusive access is reserved may include many units, e.g. a whole database, or several databases.
Ressource reservation
Ressource reservation is a scheme for realizing mutual exclusion; may be realised through semaphores or monitors (as programmable in Java)
- Historical note: Dijkstra (at the University of Eindhoven in Holland) constructed in 1965 THE operating system (probably the first multi-tasking operating system); and he had problems sharing the different computer resources (CPU, memory, disk, etc.) among the different concurrent applications. He programmed in machine language and noticed that, given the list of instructions available on the computer, it was impossible to realize reliable ressource sharing among concurrent processes. He then proposed a new instruction, sometimes called "test and set", which he introduced as part of concept of a semaphore. The semaphore is an object that supports two operations: P (for reserve: it tests whether the value of the semaphore is > 0; if that is the case, the value is decremented by one, otherwise the process has to wait) and V (for liberate: the value of the semaphore is incremented and one of the waiting processes (if there is one) is allowed to try its P operation again). An application must call the P operation before accessing the ressource associated with the semaphore, and must execute the V operation when it does not need the ressources any more.
- Conclusions:
- A semaphore is a very simple primitive for programming and controlling concurrency
- One cannot control concurrency with operations (machine instructions) that are solely conceived for sequential programs
- However, much later, Lamport described the Bakery algorithm (see Wikipedia) that provides mutual exclusion based on individual read and write operations on shared variables (where the write operations must be atomic).
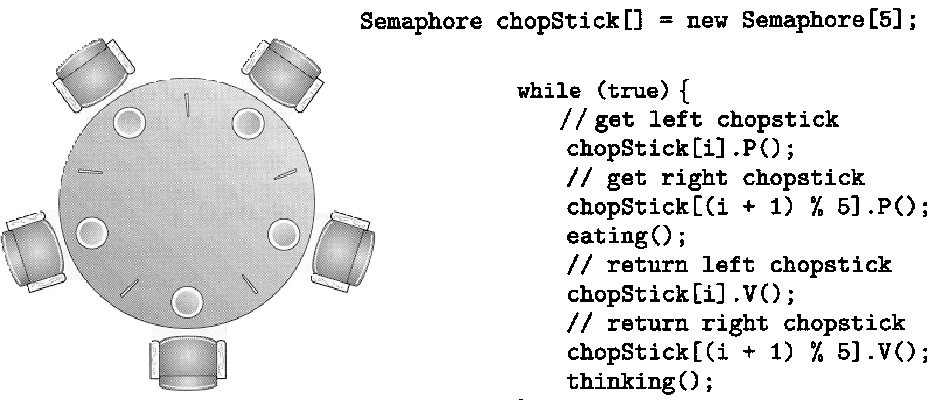
- More complex concurrency rules: Often one wants to describe more complex concurrency rules, beyond simple mutual exclusion. Examples are: (a) the readers-writers-problem (where several readers may access the ressource concurrently), and (b) the tutorial example of the dining philosophers proposed by Dijkstra (each philosopher needs to reserve the left and right fork in order to eat; there may be conflicts and the possibility of deadlocks due to a cyclic "wait-for graph". Here is the code for a philosopher who is initialized with the parameter i which indicates at what position he is on the table.
- Deadlocks
- Necessary conditions:
- mutual exclusion
- hold and wait attitude: while keeping a given ressource, a process may ask for another ressource
- no preemption
- possibility for circular waiting chains
- Strategies for dealing with deadlocks
- prevent: prevent the above conditions (at least one)
- avoid: organize the system such that no circular waiting will occur. One example of such a scheme is the so-called two-phase ressource reservation: the ressources are ordered, and each process must first reserve all ressources required for its task, and request the reservations in the order of the ressources; afterwards, all ressources must be released.
- deadlock detection and recovery: this requires a mechanism to detect the occurrence of a deadlock and a scheme for un-doing the actions of one of the processes involved in the deadlock (which may retry is actions later). In the case of transaction management, this means that one of the transactions involved in the deadlock cycle must be aborted.
The monitor concept
- Historical note: 1967 Simula (first OO language, defined by Dahl in Norway); 1972 Pascal (defined by Wirth in
Zurich, Switzerland); 1976 Concurrent Pascal (defined by Brinch-Hansen,
a danish emigrant to the US) : This language combines the simplicity of Pascal with the concept of Class from Simula and introduces the concept of controlling ressource sharing for concurrent processes by Monitors.
- A monitor is an instance of a Class with the following properties:
- The execution of concurrent calls of methods are mutually excluded in time (in Java, this is indicated by using the synchronized keyword)
- The possibility of using within the body of methods the operations wait (terminating temporarily the mutual exclusion until some programmer-defined condition - depending on internal monitor variables and method parameters - is satisfied), and notify (executed just before terminating a method call - used to activate any waiting process that will again check its waiting condition which may have been modified by the process that executed the notify operation).
- A semaphore is a special case of a monitor.
- In Java, each object instance (that inherits from the Object class) can be used as a monitor; the keyword synchronized indicates the need for mutual exclusion for a given method and the operations wait and notify (or notifyall) are defined on any instance of Object.
Concurrency in Java (Please read in the book by Sebesta)
Examples:
- A FIFO queue with producer and consumer process are given in the book by Sebesta (see copy (a) of the Queue class (note: there is a bug in the incrementation of the pointer variables, such as nextIn) and (b) of the producer and consumer classes that call an instance of Queue. At the end, there is the main program that creates instances of these objects and passes the Queue instance to the producer and consumer when they are constructed.
- Note: A very similar example is provided by SUN's Java tutorial under the title "Guarded Blocks").
- Here are some additional Java programs using semaphores and other kinds of monitors.
Some additional questions:
- How could one implement the monitor concept in Java in the Java Virtual Machine (suppose you have to design such a machine)
- Program the example of readers and writers in different versions (different versions of priorities).
Initialement écrit: 22 mars 2003;
mise à jour: 19 mars 2004; révision typographique: 4 avril 2005; translated to english: March 3, 2008, revised 2009, 2010, 2011, 2013
{kind=link}
{kind=link}
{kind=link}