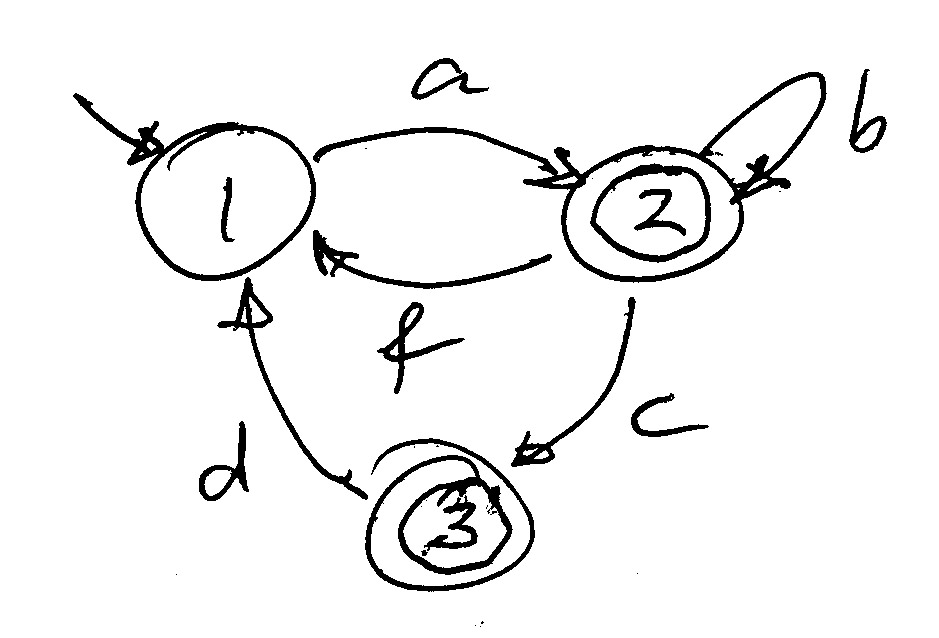
Given an accepting automaton, for instance the following, we want to determine what is the set of accepted sequences for each of the states of the automaton. For instance, we know that є is included in this set for each accepting state (since one may stop here). If there is a transition labeled x from state si to sj, then we also know that the set of sequences accepted by si include all the sequences accepted by sj to which we have concatenated in front the symbol x. If we write Si for the set of sequences accepted by state si, we can write " Si includes x . Sj " which is sometimes written " Si --> x . Sj " .
For the automaton above, we therefore can write down the following system of equations:
S1 = {a}S2
We can find a solution to this system of equation by substitution and use of Kleene's operator as follows:
substitute S3: S2 = {є} U {c} ({є} U {d}S1) U {b}S2 U {f}S1
The above recursive equations can be written as a grammar as follows:
S1 → a S2
We see that all the right sides of rules have the form x Y or є (where x is a non-terminal and Y is a terminal symbol). If all rules of a grammar are of such a form then the grammar is called a regular grammar, because it corresponds to an automaton, and it defines the (regular) language accepted by that automaton. (Question: do you see the algorithm for constructing the corresponding automaton, given a regular grammar ? )