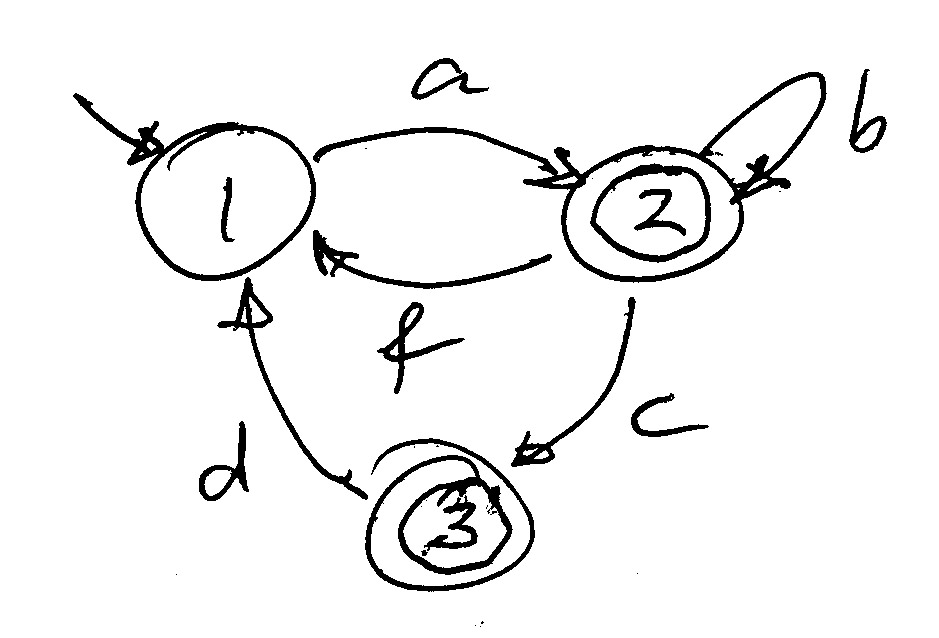
Étant donné un accepteur, par exemple celui ci-dessous, nous sommes intéressé à déterminer l'ensemble des séquences acceptées pour chaque état de l'automate. Par exemple, on sait que є est inclu dans cet ensemble pour les états qui sont acceptants (puisque l'on peut s'arrêter ici). S'il y a une transition avec étiquette x de l'état si à l'état sj, alors on sait que l'ensemble accepté par si doit inclure toutes les séquences qui commences par un x et qui s'ensuivent avec une séquence acceptée par sj. Si l'on écrit Si pour l'ensemble des séquences acceptées à partir de l'état si, on peut écrire " Si inclut x . Sj ".
Pour l'automate ci-haut, on peut donc écrire le système d'équations suivant:
S1 = {a}S2
Voici une autre notation pour écrire le même système d'équations - cette notation est utilisée pour définir des grammaires hors-contexte - voir chaptre suivant (ici nous avons une version spéciale de grammaires, les grammaires appelés grammaires régulières):
S1 --> a S2
On peut trouver une solution au système d'équation (le premier ci-haut) en substituant dans l'expression pour S2 les variables S1 et S3 par leur définition, et en utilisant ensuite l'opérateur de Kleene comme suit:
S2 = {є} U {c}({є} U {d}S1) U {b}S2 U {f}( {a}S2 ) = {є} U {c}({є} U {d}({a}S2)) U {b}S2 U {f}( {a}S2 )
Les équations ci-hautes peuvent être reérites en grammaire comme suit:
S1 → a S2
We see that all the right sides of rules have the form x Y or є (where x is a non-terminal and Y is a terminal symbol). If all rules of a grammar are of such a form then the grammar is called a regular grammar, because it corresponds to an automaton, and it defines the (regular) language accepted by that automaton. (Question: do you see the algorithm for constructing the corresponding automaton, given a regular grammar ? )