Introduction to langages and compilers
Course notes for Section 2, Chapter 2.1 of the course SEG
2106
by Gregor v. Bochmann, February 2004 (translated to English: January 2008, revised 2009, 2010, 2012, 2013, 2015)
Natural langages
In a (natural) language, a sentence is a sequece of words, and a word (also called lexemes of lexical units) is a sequence of characters (possibly a single one). The set of characters used in a language is finite. The set of possible sentences that can be formed in a language is infinite (there is no limit on the lenght of a sentence). One uses a dictionary to list all words of a language. These words (or lexemes) are usually classified into different lexical categories, such as verb, noun, pronoun, preposition, etc. One uses a grammar (also considered a set of syntax rules) to determine which sequences of words are well-formed (that is, those that are part of the language). The well-formed sentences have normally some meaning that humans can understand.
Examples of sentences (in french)
- le lapin voit le renard.
- la mouche sent le fromage.
- le lapin est gris.
- la mouche est grise.
- le lapin voit le renard rouge.
- le lapin gris voit le
renard.
- le lapin voit le renard qui
regarde la souris.
- la mouche sent le fromage qui émet une odeur.
- le lapin voit le renard qui
regarde la souris qui mange une noix.
- le lapin voit le renard qui regarde la souris qui est grise.
- le lapin voit le renard qui est gris.
- le lapin qui est réveillé voit le renard.
- le lapin qui voit le renard est réveillé.
- le lapin qui voit le renard qui
voit la souris est réveillé.
- le garçon donne le livre à la
fille.
- le garçon donne le livre qui
transmet la tradition qui est importante à la génération future à la fille.
Analysis of sentences in three levels:
- Lexical analysis: identification of words made up of characters
- the words are classified into several categories: articles, nouns,
verbes, adjectives, prepositions, pronouns, special words (is, and, if, etc.)
- Dictionary: list of words in each category
- Each category of words (like a class of objects) has certain attributes: e.g. an article has gender, a verb may be transitive or intransitive.
- Many languages have elaborate rules about conjugation and declination (not so much in English)
- Syntax analysis: rules for combining words to form sentences
- syntax rules: possible orders of word categories, e.g. article - noun - verb - article - nom
- one uses recursive rules: for instance, relative propositions like: "who/which" - verb - article - noun followed again by a relative proposition, etc.
- context rules: additional constraints in relation with the attributes of the lexical categories. E.g. the gender of an article must follow the gender of the noun.
- Analysis of meaning: difficult to formalize
Examples of (french) sentences that have problems
- voit lapin.
- le lapin mange gris.
- la lapin est gris.
- le lapin est grise.
- le garçon donne le livre qui
transmet la tradition qui est important à la génération future à la fille.
- la mouche sent le fromage qui regarde la souris.
Object-oriented view of sentence analysis
- Lexical analysis: Each category of words corresponds to a class of objects (words) that has certain attributes. All classes are specializations of the class Word with the attribut Spelling (the character string that represents the word). Here are some examples:
- Noun : with attribues Gender (with value male, female, neutre), Plural (boolean).
- Article : with the same attributes.
- Verb : with the attributes Person (with values 1, 2, 3), Plural (boolean), Mode (with values present, past, future, etc.)
- Note: the attributes are important to verify the grammatical constraints of a sentence.
- Syntax analysis: One distinguishes different "syntactic categories", that is, different components of sentences. One also may consider them as object classes. Each category has certain rules that determine how an object of that class may be composed out of words and other syntatic categories. All categories are specializations of the category Component which has the attribute Spelling that contains the character string representing that part of the sentence. Here are some examples of syntactic categories:
- Simple-sentence: there are different (alternative) rules for forming simple sentences; the following is one such rule:
- It contains, in the order from left to right, the following sub-components: Article, Noun, Verb, Complement
- Complement: It can be constructed by one of the following alternate rules:
- nothing (non existing)
- Article, Noun
- Article, Adjective, Noun
- Composed-sentence : Could be formed according to one of the following rules:
- Simple-sentence, Conjunction, Simple-sentence (for instance, the sentence: "the rabbit sees the fox but the fox sleeps")
- Simple-sentence, Conjunction, Composed-sentence (Note: this rule is recursive - Composed-sentence appears in its own definition - this allows the construction of arbitrary long sentences.)
- Exercise: Give some additional syntactic rules that could be applied to explain sentences such as "the rabbit that is awake sees the fox".
- One sometimes forms tree structures to represent the structure of sentences. They show how a sentence is formed from syntactic catagories and words of certain lexical categories. These trees are called syntax trees. Here is the example of the syntax tree for the sentence "the rabbit sees the fox but the fox sleeps":
-
Phrase-composée
- /
|
\
-
Phrase-simple
Conjunction Phrase-simple
- / /
| \ but /
| \
- Article Nom Verbe Complément-d-objet
Article Nom Verbe
- the rabbit
sees /
\ the fox sleeps
-
Article Nom
- the fox
- One calls the objects that are on the leafs of the syntax tree "terminals", and the other objects at the internal nodes of the tree "non-terminals". We see, the terminals are words, the non-terminals are syntactic catagories.
Computer languages
Similarly, in computer (or programming) languages, one speaks about a program (corresponding to a sentence) which is a sequence of lexical units, and the lexical units (or lexemes) are sequences of characters.
- The lexical rules of the language determine what the valid lexical units of the language are; one distinguishes normally different lexical categories, such as indentifier, reserved identifiers, number, character string, operators, separators, etc. (Note: certain books use the term "token" to designate a lexical category) [see examples].
- The syntax rules of the language determine what sequences of lexemes are well-formed programs.
- The meaning of a well-formed program is also called its semantics. Depending on the language, the semantics of a program could be the computing function that the program represents, or the dynamic behavior of the real-time system represented by the program, or other things.
Language processing
A compiler translates a well-formed program in the source language into object-code (a program written the target language). Normally, one wants that the semantics of the generated object-code (as defined by the target language) is the same as the semantics of the program (as defined by the source language). Sometimes one also says that the semantics of the source program is the semantics of the object-code generated by the compiler, however, this definition is usually not very useful since the semantics of the generated object-code would be difficult to understand.
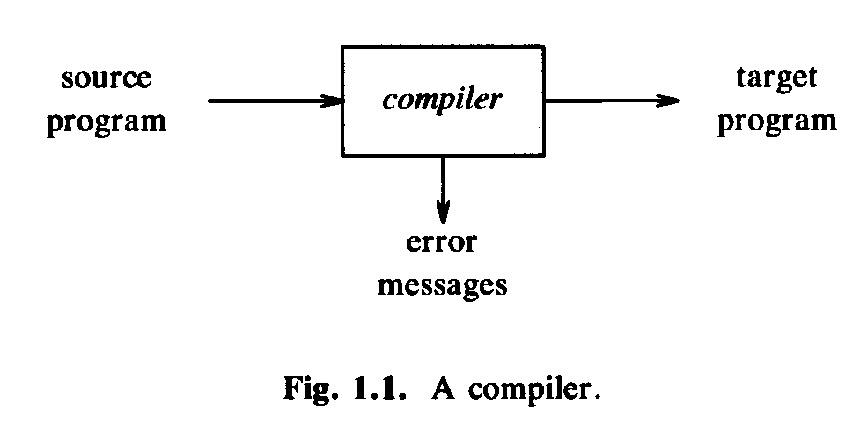
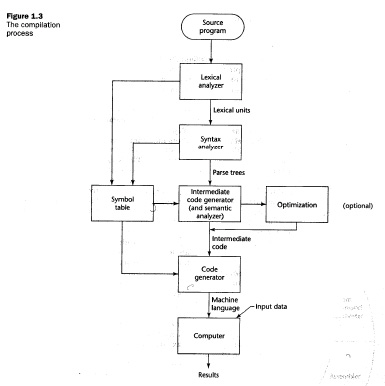
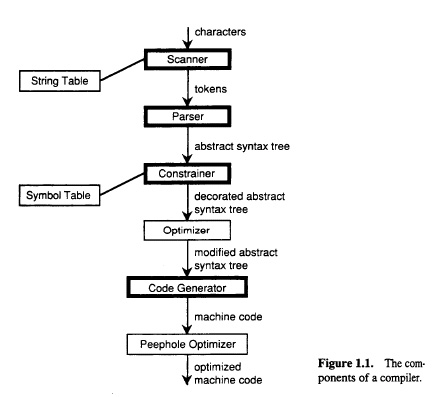
A compiler usually realizes the translation is several steps; correspondingly, it contains several components. This may be represented by different diagrams, such as the following: Version-1 , Version-2. Usually, a compiler includes (at least) separate components for verifying the lexical and syntax rules:
- The lexical rules determine which sequences of characters are valid lexemes, and
- The syntax rules determine which sequences of lexemes are valid programs. The syntax rules are normally defined in two steps:
- so-called context-free syntax rules that are defined in the form of a context-free grammar (see chapter on syntax analysis), and
- so-called semantic constraints that are additional constraints that a valid program must safisfy (for instance, type checking rules in Java programs)
These rules can be defined in different manners and using different formalisms. In general, syntax rules are more complex than the lexical rules. Therefore the formalism used to express the syntax rules of a language is normally more powerful than the rules used for describing the lexical rules. Certain formalism may be used for both purposes, comme for instance the context-free grammars (see chapter on syntax analysis).
In general, there are two problems to be dealt with in relation with computer languages (and also for natural languages when they are processed by computers):
- Generation of all valid programs (for instance, generation in the order of their length, if their number is infinite)
- Recognition (or analysis) of all valid programs, that is, for any given program determine whether it is well-formed or not.
Certain definition formalisms are more suitable for the generation problem, while others are more suitable for the recognition problem. Clearly, a compiler has to resolve the recognition problem.
In the following two chapters of this course, we will discuss lexical analysis and syntax analysis.
Last update: February 3, 2015
{kind=link}
{kind=link}
{kind=link}