Building a compiler for VSPL
Recall the Syntax of SVPL:
- <program> --> begin <statement list> end
- <statement list> --> <statement> ; <statement list>
- <statement list> --> <statement>
- <statement> --> <id> := <expression>
- <expression> --> <id> + <id>
- <expression> --> <id> - <id>
- <expression> --> <id>
Requirements for the Java program:
The Java program should read (on the standard system input file) a program written in
the Very-Simple-Programming-Language and produce as output (on the standard system output
file) either an appropriate error message (if the program contains a syntax or semantic
error), or a list of integer values equal to the values of the expressions contained in
the assignment statements of the program (and in the order in which they are contained in
the program).
Solution:
Please read again the following sections in the course notes: "Syntax Diagrams" and "Example: different grammars for expressions and static evaluation
of the values of expressions" in the section on "Semantic Attributes".
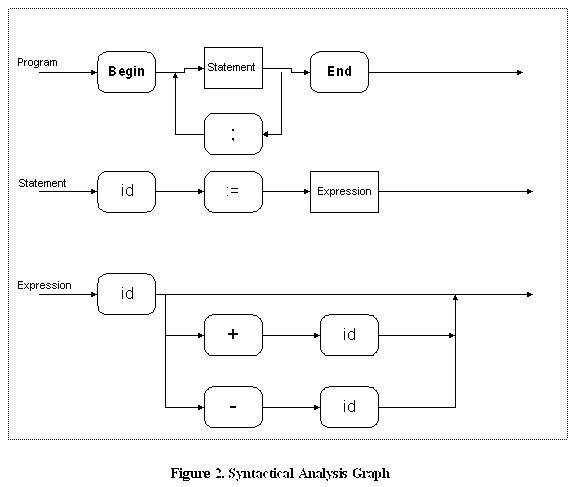
We use recursive descent syntax analysis. This means that the compiler will contain a recursive procedure for each non-terminal of the grammar: <program>, <statement list>, <statement> and <expression>. However, <statement list> can be eliminated by noting that the rules (2) and (3) may be replaced by the rule (extended BNF, including the Kleene star): <statement list> --> ( <statement> ; )* <statement> and then substituting the regular expression on the right side into rule (1), resulting in the following: <program> --> begin ( <statement> ; )* <statement> end .
Then we can write down (recursive) automata, one for each non-terminal, as follows (we have seen an example of such a recursive automaton in the discussion of the grammar of regular expressions at the beginning of the chapter on syntax analysis):

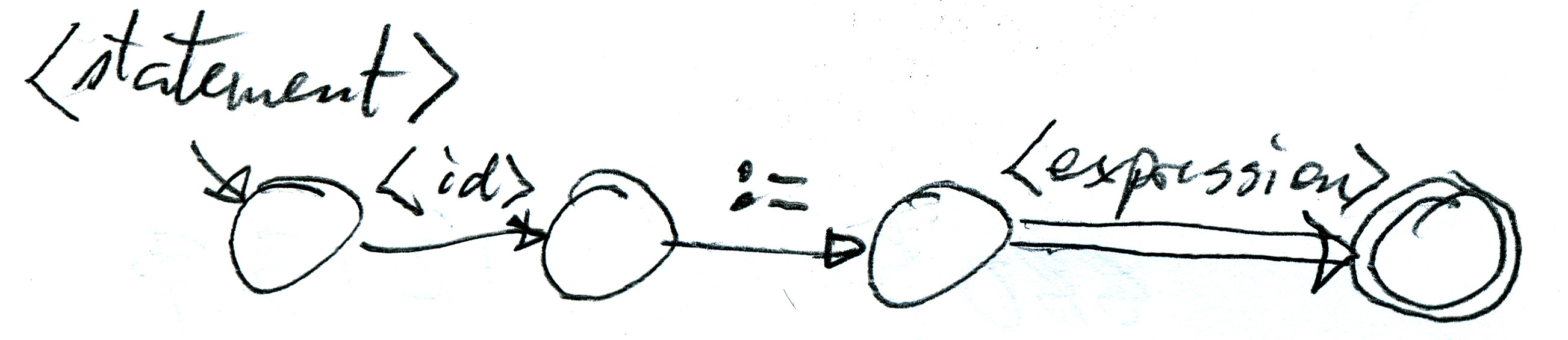

This can also be written in the form of a so-called syntax
graph . These recursive automata (or the corresponding syntax graphs) can be easily translated into Java code, as shown in the Syner class in the Java program called SimpleCompiler.
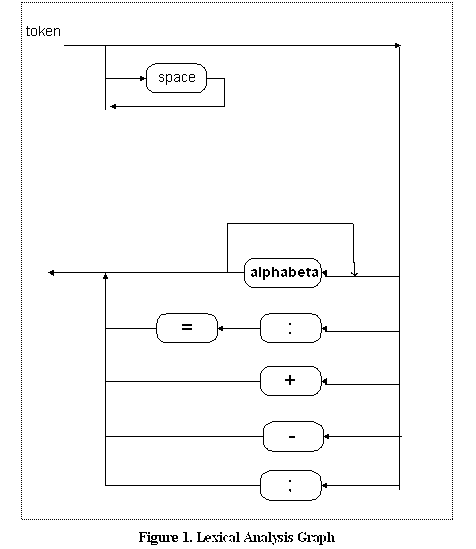
Similarly, one can write down a syntax graph
for the lexical analysis and construct a corresponding Java program which is given in the form of the Lexer class of the SimpleCompiler. Here is an example program
that has been analyzed by the SimpleCompiler and has produced the following output.
Notes on the SimpleCompiler program:
- Besides a simple class SimpleCompiler, which represents the "main" program,
there are essentially two classes, one representing the lexical analyzer and one representing the syntax
analyzer.
- The lexical analyzer class exports the definition of the tokens for this language
(constant definitions) and has two exported variables (attributes): token which always
contains the next token from the input file, and idName which contains the name
of the identifier if the token is an identifier. It also exports the procedure getNextToken()
which analyses the next token in the input file and puts it into the token variable. When
an end of file has been encountered the token EOF is returned. The lexical analyzer also has a hidden
variable c which always contains the next character (that is, the last character
read from the input file). The procedure nextChar is used to get the next
character from the input file. It also prints the character on the system output file if
the option makeCopyOnOutput is selected.
- The syntax analyzer works as explained in Sebesta's book. There is an analysis procedure
for each nonterminal shown in the syntax graph. The procedure startAnalysis,
which is called by the main program, will call the syntax analysis procedure for the
<program> nonterminal. It also handles the end of the program.
When the input file has been successfully analyzed, a subsequent call on the getNextToken
of the lexical analyzer checks whether there are more non-space characters in the input
file. Normally, this call should result in the return of the EOF token. If this is not the case, then there is some additional input available and an
appropriate error message is prepared.
- Please, note that there is a very simple symbol table in the syntax
analyzer, which stores the names and values of variables. The name of the variable is used as the key for accessing the information.
- The procedure parseExpression returns an integer number which represents the value of the expression. This corresponds to a semantic attribute of the expression which is the value of the expression in this case. If a nonterminal has several semantic attributes, then it is more convenient to let the parsing procedure return an instance of a object that has an attribute for each semantic attribute of the nonterminal.
{kind=link}
{kind=link}