Additive depth maps, a compact approach for shape completion of single view depth maps
| Po Kong Lai, Weizhe Liang and Robert Laganière University of Ottawa Ottawa, ON, Canada |
|
|---|---|
| Questions? Drop us a line | |
Overview
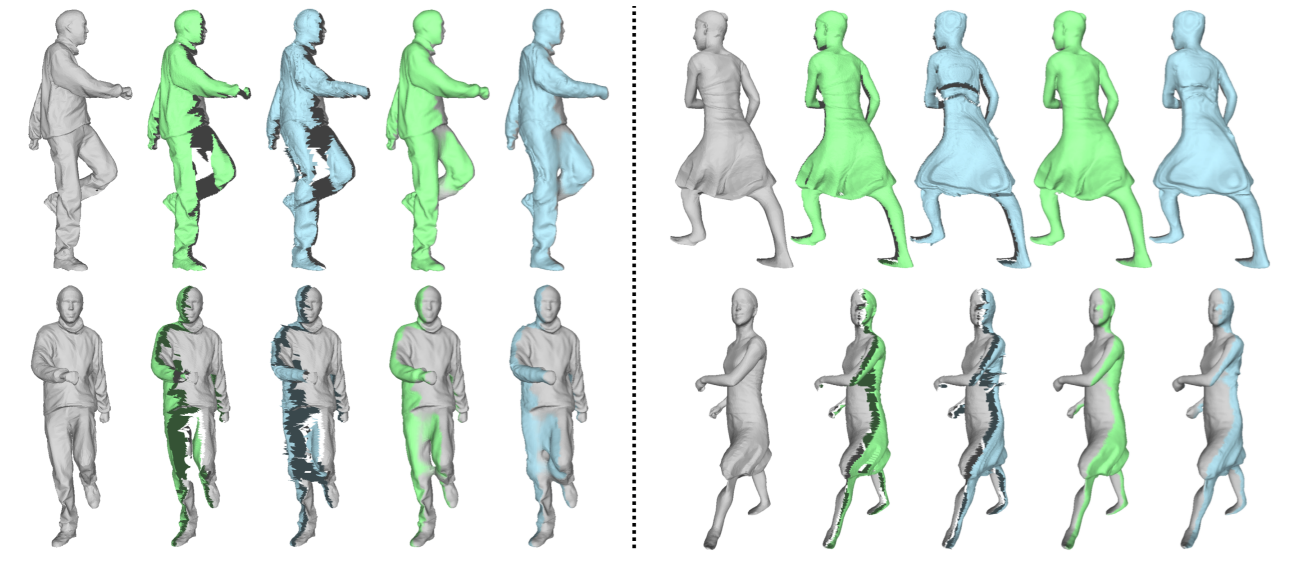
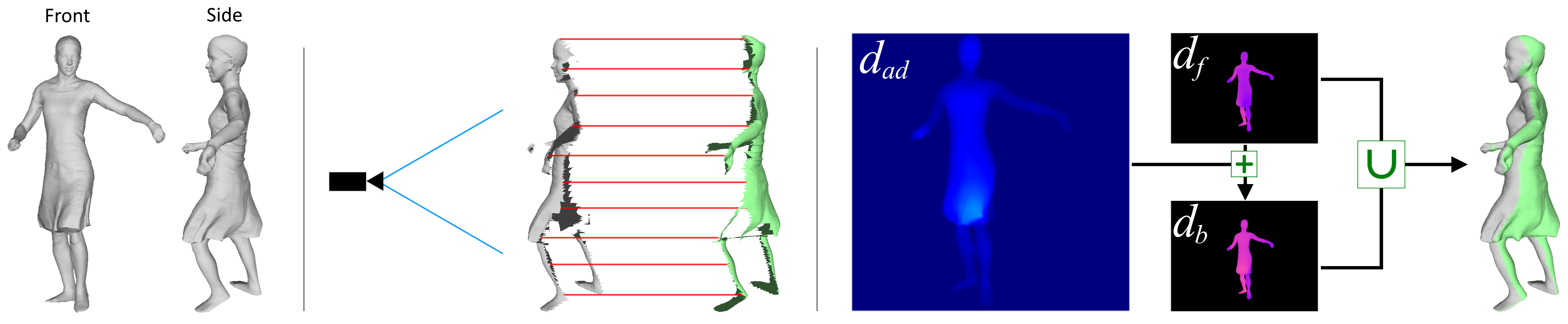
The ability to complete and reconstruct the 3D geometry of an object from a single view depth map is particularly useful for VR/AR applications, robotics (ie: grasping objects), obstacle avoidance and content creation. However, reconstructing the 3D shape of objects from a single depth map is very challenging due to the inherent ill-posed nature of the problem - potentially infinite configurations and arrangement of shapes can produce the same depth map. In our work, Recent state-of-the-art approaches use a 3D skip-connected auto-encoder style network where the input and output is either a voxel occupancy grid or a signed distance field (SDF). These 3D networks essentially replace the 2D pixel array with it’s 3D analogue - a dense 3D voxel grid. Thus, computational and memory requirements for these networks scale cubically. As a result, these networks are typically trained with low resolutions (323 voxels) often leading to coarse outputs. In our work, we introduce the concept of an “additive depth map” as a compact representation for 3D shape completion and propose a 2D CNN to predict it. Our contributions are as follows:
- The additive depth map as a minimal representation for 3D shape completion from single view depth maps which can preserve thin structures..
- A network which can prediction the additive depth map in real time (~14 fps).
- We show experimentally that the additive depth map can achieve state-of-the-art results for single category 3D shape completion. Additionally, we show that our approach performs well on real world data after being trained purely on synthetic datasets.
Proposed approach
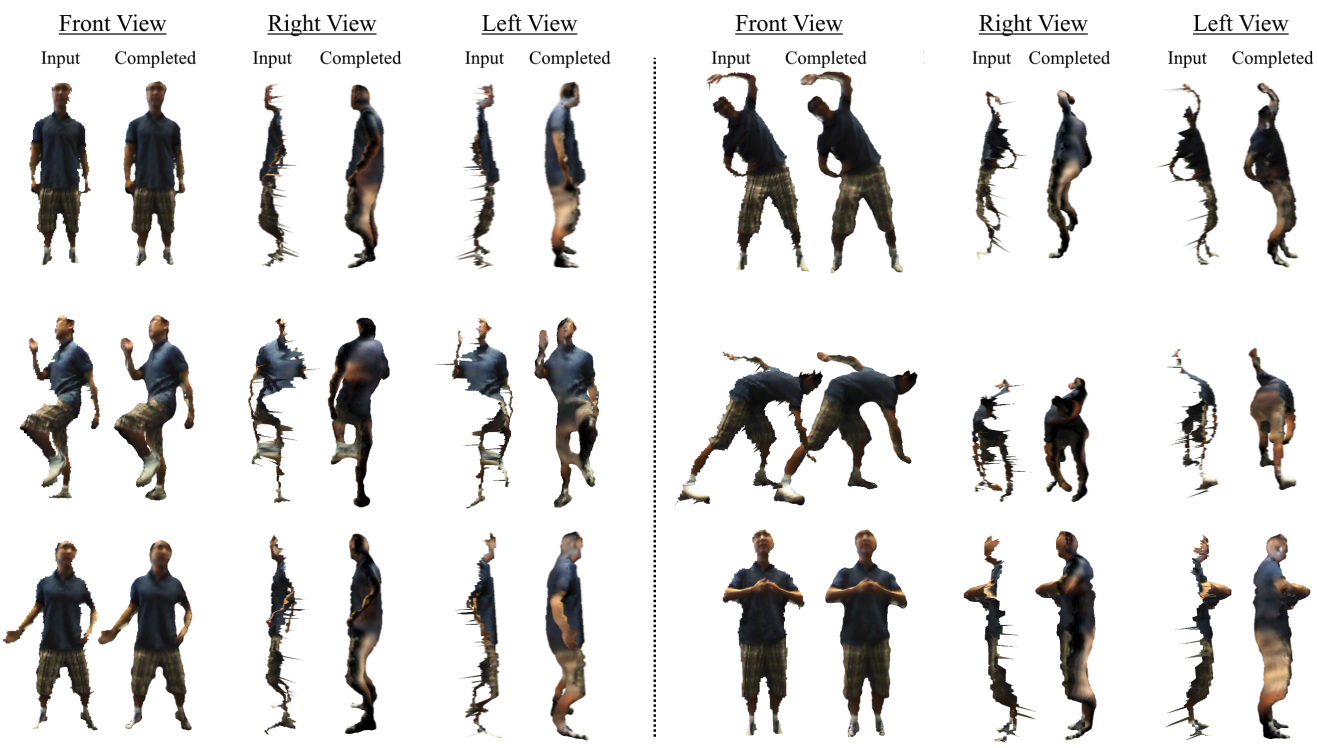
Example output