Deep People Detection: A Comparative Study of SSD
and LSTM-decoder
| Md
Atiqur Rahman, Prince
Kapoor, Robert
Laganière University of Ottawa Ottawa, ON, Canada |
Daniel
Laroche, Changyun
Zhu, Xiaoyin
Xu,
Ali Ors NXP Semiconductors Ottawa, ON, Canada |
|---|---|
| Questions? Drop us a line | |
Overview
This study seeks to provide
an extensive comparison between two state-of-the-art deep
object detection frameworks, namely SSD [1] and LSTM-decoder
[2] in the context of people detection. The aim is to
explore the two detection architectures in terms of
accuracy, speed, robustness to occlusion and scale, as well
as generalization ability which are the leading challenges
for people detection. Our experimental results show that
while the LSTM-decoder can be more accurate in realizing
smaller head instances, especially in the presence of
occlusions, the sheer detection speed and superior
generalization ability of SSD makes it an ideal choice for
real-time people detection.
This work was accepted in the 15th Conference on Computer and Robot Vision (CRV'18) conference.
Click here for more
This work was accepted in the 15th Conference on Computer and Robot Vision (CRV'18) conference.
Click here for more
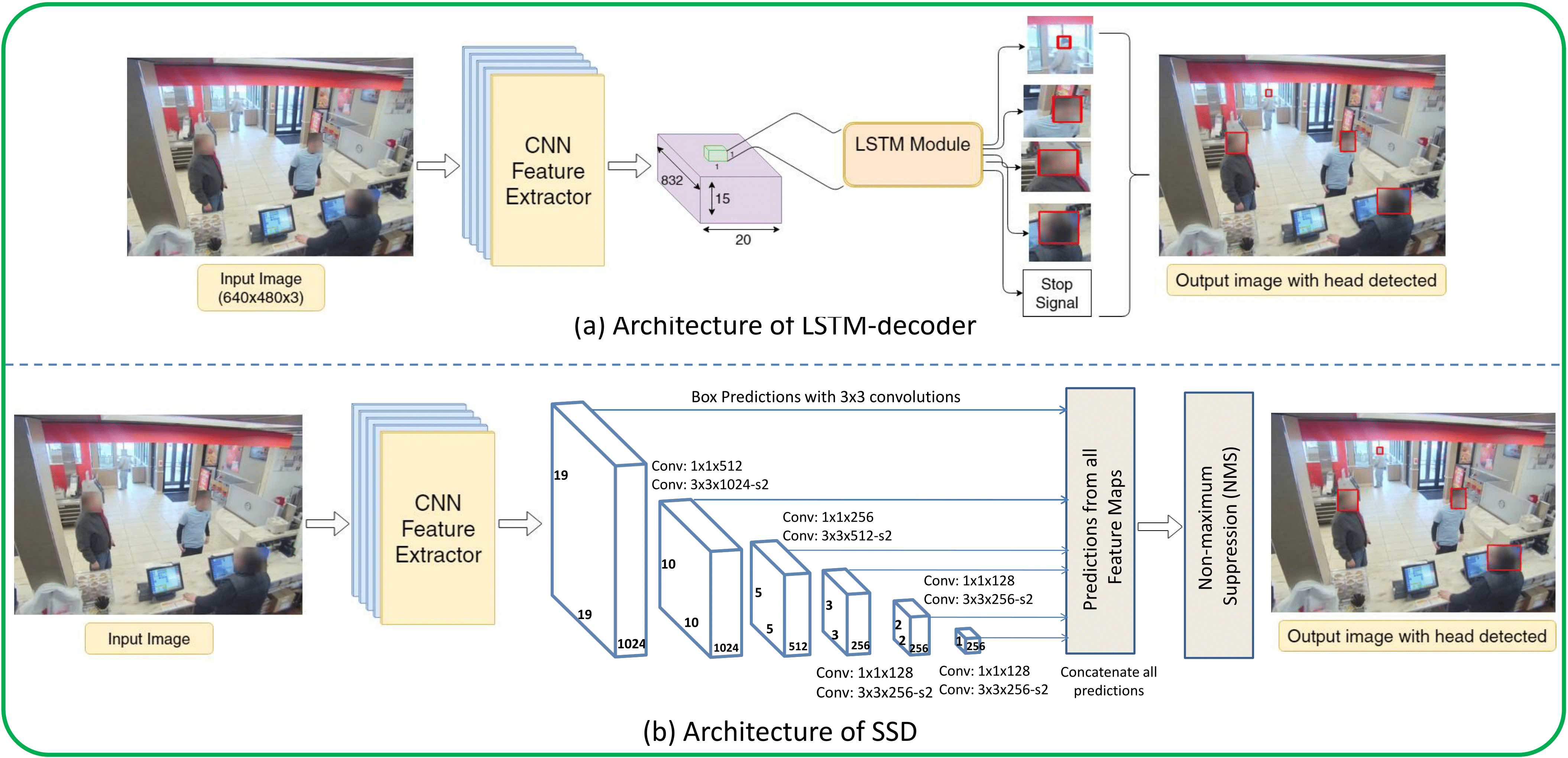
Model Architectures
The following gives an
architectural overview of LSTM-decoder and SSD models that
we study in this work.
Datasets
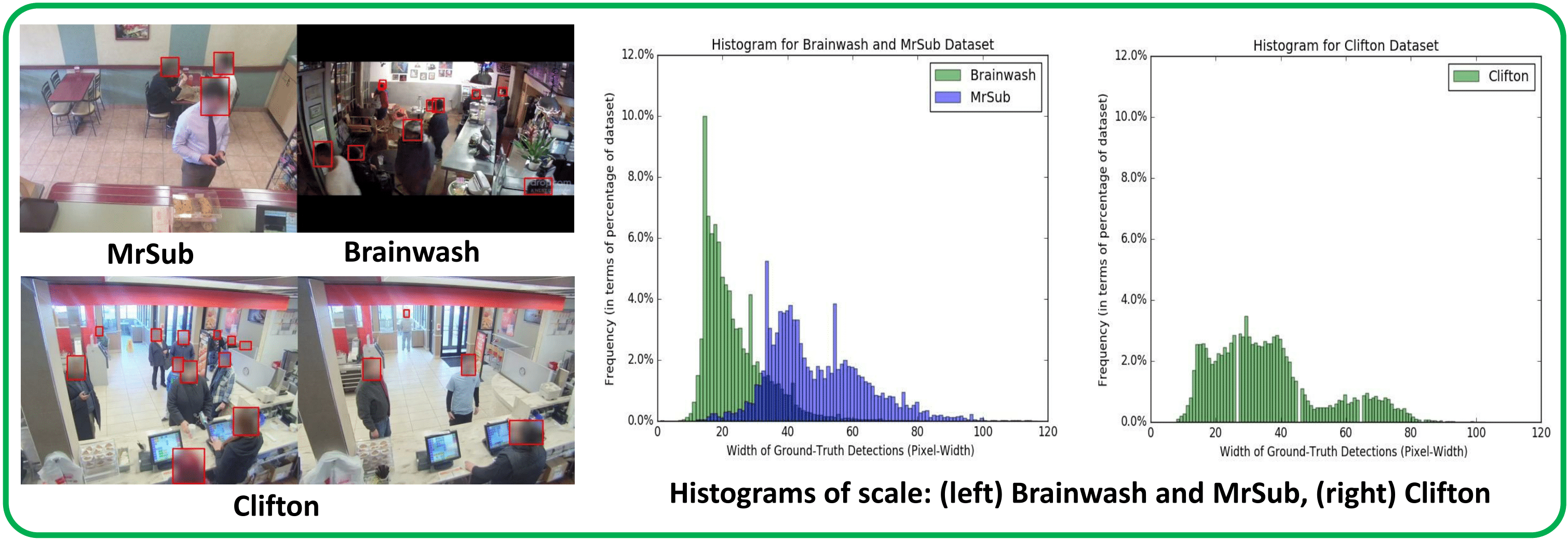
In addition to using a
benchmark head detection dataset called Brainwash [2], we
also experimented with two new datasets called MrSub and
Clifton which we collected from different restaurants.
These datasets vary widely from each other in terms of
scale and occlusion level as depicted in the below figure,
thereby allowing us to better explore the models'
robustness to variation in scale and occlusion.
Experimental Setup
The models are evaluated and compared based on 4 different experimental settings as below:
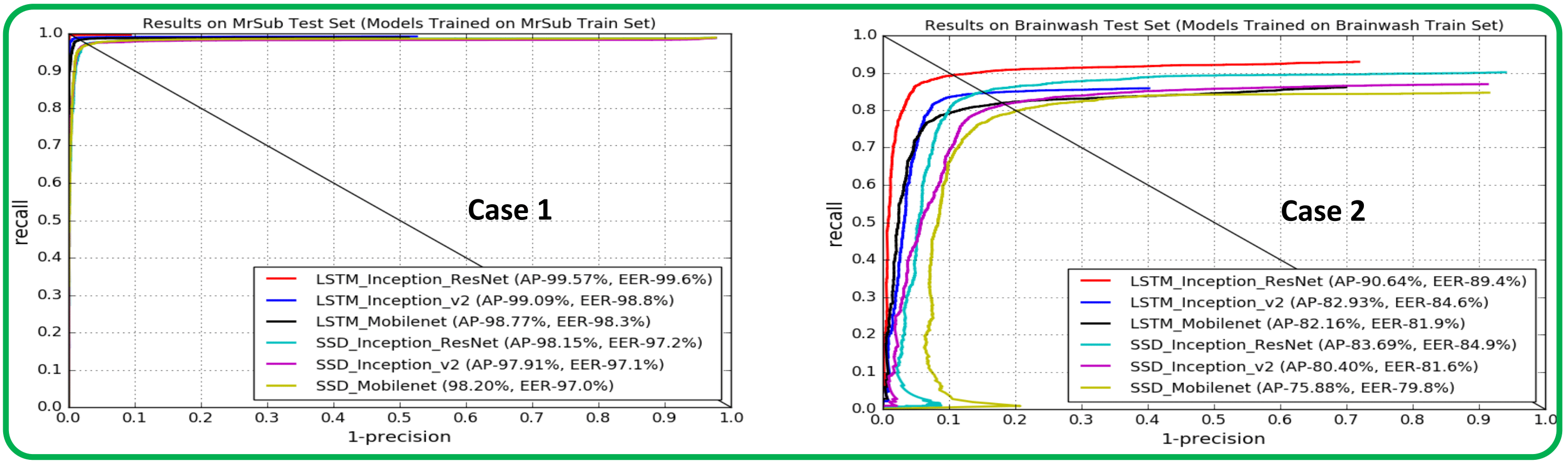
- Case 1: Models trained and tested on MrSub to analyze the baseline performance. MrSub, as obvisous from the above figure, is the easiest among the three datasests with large scale and very less occlusion.
- Case 2: Models trained and tested on Brainwash to analyze the robustness to occlusion and tiny-scale. Brainwash is a highly occluded and tiny-scale dataset.
- Case 3: Models trained on Brainwash, tested on MrSub to analyze the generalization ability over different scales. Brainwash and MrSub clearly have different distributions of scales.
- Case 4: Models trained on Brainwash+MrSub, tested on Clifton to analyze the domain adaptation ability. Clifton has a distribution of scale and occlusion level which is a mixture of Brainwash and MrSub.
Results
The Recall vs.
(1-Precision) curves corresponding to the 4 different
cases are depicted below. For each model architecture, we
plot 3 different curves corresponding to three different
CNN feature extractors (e.g., Inception-Resnet-V2,
Inception-V2, and Mobilenet)

Some of the sample
detections along with the inference time for the two
models are shown below.

References
- W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in ECCV, 2016.
- R. Stewart and M. Andriluka, “End-to-end people detection in crowded scenes,” CoRR, vol. abs/1506.04878, 2015.
Navigation
Industry Partners
Thank you to NXP Semiconductor for making this work possible!